Highlight

Successful together – our valantic Team.
Meet the people who bring passion and accountability to driving success at valantic.
Get to know usA lot has happened in the SAP Datasphere since the last blog post. Approximately every two weeks, the planned wave deployments bring a lot of updates. This time, the focus is on data modeling and data integration. And the innovations in the area of file space in object memory are especially important. The following is a summary of the most exciting innovations that have been released since mid-March. Our last blog post provided an overview of the updates from January to March.
One very promising innovation is the object store. It provides a resource-efficient entry layer for the provision of large amounts of data. Administrators can create file spaces in the object database. This principle is already familiar from classic spaces. Data can only be loaded in a file space through replication flows and then stored in a local table (file). It is not possible to import or export CSV/JSON files. Optionally, the local table (file) can then be prepared further with a transformation flow. Subsequently, the prepared file can be shared with a classic space and used as a local table there.
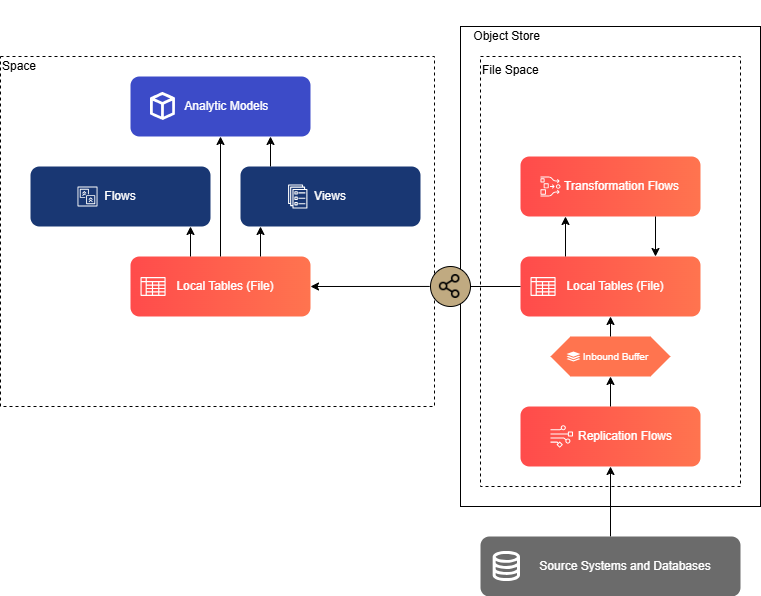
When data is loaded through the replication flow, data files are first written to an input buffer of a local target table (file). The input buffer is a special folder in the file memory. To process the data update and make it visible in the local table, a merge task must be performed. This can be implemented using a task chain or the monitor “Local tables (file).”
In the monitor, the merge task can be performed directly or regulated and optimized with a schedule. At the same time, it is possible to customize the resources for the workload you need. In addition, the monitoring of the local tables (file) takes place in the monitor. This allows an overview of all local tables (file) regarding their status regarding the merge, update times, or whether, for example, delta capture is activated.
The processing and preparation of the data is implemented through transformation flows. When it is created in the file space, a number of computing resources can be assigned to it to ensure constant operation of the system and avoid temporary overloads. The number of computing resources can also be updated if the transformation flow or computing resources change.
If a transformation flow has to be canceled, in the future it will be possible to cancel it under the options with or without rollback. If it is determined that the transformation flow does not bring the data into an unintended state, a cancellation can be initiated with rollback. This redirects the local table and any parallel changes from the other apps to the state that existed before the start of the transformation flow. By contrast, canceling with rollback allows you to preserve all the data already processed and interrupt the transformation flow, which can be resumed from the point of interruption. This can be useful if there is a short-term need for computing resources or if changes are reviewed.
Transformation flows in general have also been updated. In addition to the function to simulate a run, the option to generate an explain plan has been introduced. It generates a compiled plan as a table in which individual steps with their operators and associated information are displayed. This enables you to search for errors in detail if the simulation fails.
Another new feature of data integration is the extension of the “datasphere ” command line interface. Here it is possible to create, remove, and validate different connection types. An administrator can manage the TLS certificates. The extension of the command line interface makes it easy to perform common maintenance tasks, such as managing TLS certificates by scripting or creating or editing connections for specific spaces in a standardized manner. Once prepared and created, the regular workload and errors in connections can be reduced. The command line interface is available for a wide range of connection types, including Oracle, Generic OData, SAP BW, Confluent, SAP S/4HANA Cloud, and more. For replication flows, the updates now allow the use of Microsoft SQL Server as a connection type, which can also be managed via the command line interface.
SAP continues to expand the range of connectivity options while providing an efficient management capability with the command line interface.
The latest enhancements to SAP Datasphere data modeling also introduce new data modeling capabilities for the file space. A wider range of standard Python libraries has been added to the Python file operator in the transformation flows. This enables you to load and prepare large quantities of data in the cost-effective object storage of the file space instead of doing this in a classic space later in the data flow. For an overview of the Python operator functions, there is a reference page.
Updating the Python file operator can increase the number of computing resources required. A new function has been introduced for the task chains in the file space. You can now update the maximum usable number of computing resources in a step. In the future, it will be possible to react flexibly to the changes of an object without creating a new task chain.
Regardless of the object storage, there are also crucial innovations in data modeling. A new feature allows the validation of data on views with remote sources to be used. Previously, it was necessary to persist the data before a validation could be performed. The validation checks whether the primary key values are not NULL and are unique. The hierarchies are checked for multiple parent elements and whether a circular hierarchy exists. In addition, there is a check for consistent data types. By validating remote sources, it is also possible to detect and repair errors directly during the initial creation of a model or changes to existing models.
Another innovation in user security is the ability to restore previous data access controls. Recovery capabilities in the SAP Datasphere have been extended to include new objects in recent months, as described in the last blog post. This allows data access controls to be restored to a working state in the event of unintentional changes or errors, without having to manually undo the changes.
The administration options have been adapted for the new object storage and the extension of the existing functions. During system monitoring, it is possible to track and analyze complex instructions. If a SQL query exceeds CPU utilization, memory, or time thresholds when executed, it is tracked automatically. You can use standard thresholds or adjust them to suit your own needs. This helps handle problem source analysis in a clear way and it can detect and prevent system overloads.
In the past month, SAP has released regular updates to the SAP Datasphere. Many of the updates result in more functionalities being offered to users. Data modeling and data integration in particular benefit from the latest wave of innovations, so there’s nothing to stop embedding in the Business Data Cloud.
valantic visited the DSAG at the beginning of April. The DSAG offers exciting specialist lectures and the opportunity for members of the SAP audience to exchange ideas with each other. This year, valantic and a customer presented the conceptual approach of the jointly conducted, successful PoC in the SAP datasphere. This provided the opportunity to discuss some of the issues raised together.
If your interest in the SAP Datasphere has also been aroused or you would like to learn how the SAP Datasphere will be integrated and optimized within the framework of the Business Data Cloud, please do not hesitate to contact us!
A look at the SAP Road Map Explorer roadmap shows that we still have an interesting and innovative year 2025 ahead of us!

Artificial Intelligence July 15, 2026
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
SAP Sapphire has refined the vision of the Autonomous Enterprise—now it’s time to put it into practice. Part 2 of our blog series highlights four key building blocks: transparent architecture and agent governance with LeanIX, the path to the cloud, a solid data foundation in the SAP Business Data Cloud, and processes made visible through process mining.
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
Work@valantic June 10, 2026
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Florian Steinwendtner is Head of SAP Cloud Advisory and leads the logistics team at valantic in Austria. In this interview, he talks about his extraordinary path from landscape gardener to SAP consultant, his enthusiasm for SAP Cloud ERP, and how he is helping to drive valantic's SAP Cloud Powerhouse forward.
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Artificial Intelligence June 9, 2026
SAP Sapphire 2026 – the way into the Autonomous Enterprise
SAP Sapphire 2026 marks the mindshift from assistant to agent: In the Autonomous Enterprise, Joule Assistants orchestrate networked agents that perform routine work independently across SAP and non-SAP systems. They are based on Joule Work and Joule Studio, the SAP Business Data Cloud and the Business AI Platform - provided that the data, cloud setup and culture are in sync.
SAP Sapphire 2026 – the way into the Autonomous EnterpriseDon't miss a thing.
Subscribe to our latest blog articles.

