Highlight

Successful together – our valantic Team.
Meet the people who bring passion and accountability to driving success at valantic.
Get to know usThe last blog post summarized the various updates to SAP Datasphere in 2024 and provided a forecast of the exciting topics expected this year. Since then, some innovations have already been implemented. In addition to the new “Horizon” design, which stands out with modern and vibrant colors, SAP Datasphere has been extended to include a number of functions. The new design changed some icons, but all functionalities remain unchanged.
The following is a summary of the most exciting innovations that have been released since January. Data modeling and data integration are the focus this time, but SAP also addresses topics such as administration, the data catalog, and marketplace.
Processing large amounts of data is critical for a company’s success. In order not to impair the workflow, this should be done as efficiently as possible.
To this end, RFC (Remote Function Call) performance for replication flows of SAP-S/4HANA-On-Premise connections has been optimized. You can now enable RFC rapid serialization for existing connections, which improves performance, especially for large amounts of data. If a new connection is created, quick serialization is now turned on by default.
Active replication flows already have the ability to remove objects while preserving existing data in the destination. You can also add new objects from the source system. A third innovation is that the intervals for delta data transfer can be changed during an active replication flow, which reduces the need for interruptions and allows frequent changes to be made easily.
In addition, replication flows reduce the amount of manual work. If a column from the target table is not in the source system, it can now be ignored and the rest of the replication completed successfully. Previously, it was necessary to delete all non-existent columns in the target table manually.
To supplement the replication flows, the transformation flows also have two useful new extensions for analysis and adaptation. In the future, it will be possible to simulate a run of the transformation flow to check whether the desired result can be achieved without saving the changes in the target table. This also allows you to detect and correct any errors or performance problems at the same time.
If a simulation is not sufficient for analysis and troubleshooting, it will be possible to generate and download a PLV file (SQL plan visualization file). This gives users the opportunity to gain visual insight into the operators and their relationships as well as their hierarchies. This detailed information about the data model provides a practical option for planning changes and estimating the impact. A compatible SQL plan visualization tool, such as the SQL Analyzer Tool for SAP HANA, is required to display the PLV file.
On the analysis side, the View Analyzer has been customized and expanded. Run details, task logs, and view partitioning have been refined for ease of use, making it easy to use and get started. In addition, local tables are also analyzed in the data persistence candidate evaluation. These were previously not considered in any metrics for evaluation, so the metrics were less meaningful. The new metrics allow users to re-analyze past persistence decisions and make different decisions.
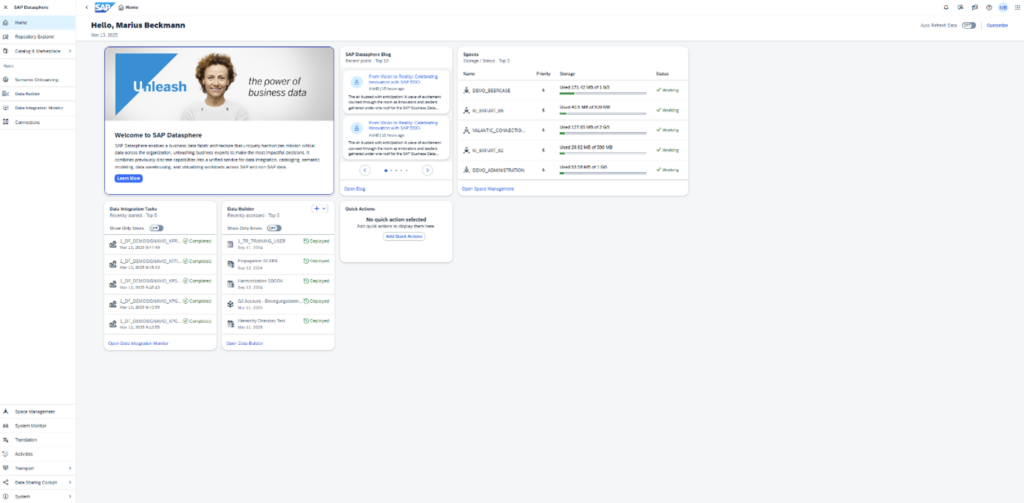
When it comes to data modeling innovations, the focus is initially on the analysis model. Here, many dimensions are often used, and attributes duplicated. Technical names can now also be assigned to them, allowing for more consistent naming and a clearer overview. As a result, the Dimensions alias was simultaneously renamed Business Name for the purpose of consistency, as it is already known under this name from views and tables.
The status of an enabled analysis model is changed to “Changes to Enable” or “Design Error” if the hierarchy changes in a dimension. The status depends on the impact of the changes.
The display of the changed status becomes particularly interesting with regard to a new feature in the hierarchies. Previously, a hierarchy in the hierarchy directory could only be identified by a single key column under the property “Column of type hierarchy name.” This property has been renamed the “Hierarchy Directory Association.” An association that refers to the hierarchy directory must be entered there. It also allows associations with compound keys. Existing hierarchies are migrated automatically, so the status of the analysis model is reset when it is used.
Another new feature of the analysis model that can be listed is the ability to set dynamic default values for variables. These can then be suggested dynamically in the analysis preview and also in the SAP Analytics Cloud variable prompt.
With an additional extension, it is possible to combine data access controls for dynamic filter-based operators and values, as well as static hierarchies and individual values. This means that data protection can be guaranteed even with versatile or large analysis models.
Another interesting update also relates to the analysis models. It is now possible to call up a list of previous object versions and perform the following actions:
The last point can be used to delete obsolete versions of local tables if the data has already been processed in flows. This can improve the performance and storage efficiency of the system.
If the local tables have enabled delta capture, another consistent innovation is added to the delta to optimize system performance and storage efficiency. You can delete records here as follows if the data change has already been processed:
Delete all records: All records in your table will be physically deleted.
Delete all records (mark as “deleted”): All records in your table will have the change type “D” but can still be processed by other apps until they are deleted permanently.
Delete all records marked for deletion that are older than the specified number of days: After the specified number of days has elapsed, all fully processed records with change type “D” will be deleted permanently.
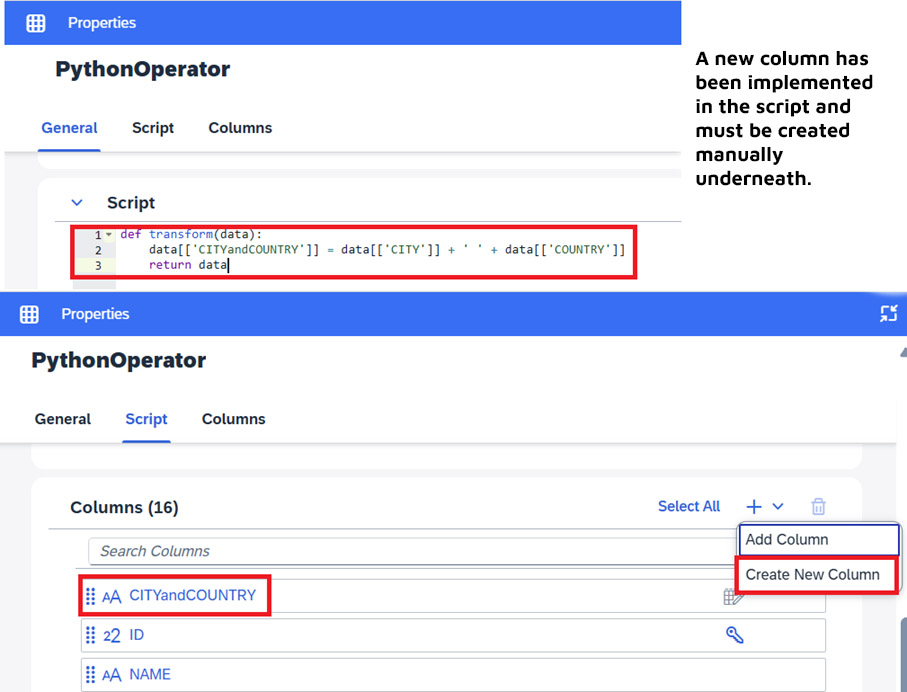
The ability to use Python has been extended in data flows. The incoming data at the Python operator can be converted and the structured data passed to the next operator. For example, the name and data type of a column can be changed in the Python operator. It is also possible to delete and add columns. Note that if a column is added in the “Script” area of the Python operator, it is not propagated automatically and is therefore not available in the next operator. The new column must also be inserted manually in the “Columns” area of the Python operator, otherwise errors may occur. The restrictions in the Python area can still be found in the SAP Python operator reference.
There is also a small but no less important innovation in SQL View transformations. For active SQL View transformations, there is a data preview option. As a result, changes can be analyzed more quickly, and it is no longer necessary to create another view in order to get a preview of the data.
For administration, the introduction of the DW AI Consumer role is a significant innovation. Optionally, a user-defined role can be assigned the right to use Data Warehouse AI. This supports natural language searching in the Data Builder area and Repository Explorer, and the input is interpreted using AI. This eliminates the need for character-specific input. For more options in the data catalog, see the Data Catalog & Data Marketplace section. However, a license for SAP AI units is required. This can be obtained from a customer advisor.
In order to redistribute resources on short notice, the option to cancel task chains has been created. This may be necessary if they require an unexpected amount of time or resources and have a negative impact on other task chains. At the same time, it is possible to react to spontaneous resource requests and control certain task chains manually, even though they have already been started.
This time around, the Data Catalog and Data Marketplace will be combined in a single blog post entry, as SAP Datasphere also follows this path. As an important innovation, these are now combined in a menu item in the page navigation. This is a central point for managing assets and data, as well as their metadata, and for managing licenses over time and participating in topics of interest to you. This enables the following functions to be accessed under the same element:
As mentioned earlier, SAP Business AI can be used to manage and enrich assets in the catalog. Summaries and long descriptions can be generated using SAP Business AI. There is now an additional “Generate summary” button in the “Edit catalog details” area. The same function can also be found under “Edit content” for the description by the “Generate” button. In addition, there is an option to support the tags in the “Semantic enrichment” area. There, you can find them in the hierarchy that contains the tags. This offers a time-saving solution and faster overview for managing and enriching assets.
In the data catalog there is now also the impact and origin analysis, which some users may already know from data modeling. It provides easy and critical assess to support understanding of a data product, such as product benefits or limitations.
In the first quarter, many new features and enhancements were introduced in SAP Datasphere, particularly with regard to data modeling and data integration. Performance has been improved in some places, while the analysis model and the basis for it have been extended.
Our recent SAP Analytics Roadshow was a tremendous success. We had enthusiastic audiences in Hamburg, Munich, Cologne, and Copenhagen. In exciting specialist talks, valantic customers reported on their path into the cloud world. These approaches were discussed in greater detail during coffee and lunch breaks. SAP was also on-site in each location and reported on the intention and strategy of the Business Data Cloud. The specialist audience was thus able to direct their questions right to SAP. The valantic team leads provided deep insights into their experiences from a variety of customer projects in talks about the SAP Analytics Cloud and SAP Datasphere. AI, something everyone is talking about, was also considered. There was an exciting talk about the latest technologies and their use in the video analysis system. This topic was rounded off with a demonstration by valantic, in which the video metadata was integrated into and modeled in SAP Datasphere via live connection and subsequently reported in the SAP Analytics Cloud.
If you are interested in learning more or you have general questions about SAP Datasphere, we will be happy to provide answers.

Artificial Intelligence July 15, 2026
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
SAP Sapphire has refined the vision of the Autonomous Enterprise—now it’s time to put it into practice. Part 2 of our blog series highlights four key building blocks: transparent architecture and agent governance with LeanIX, the path to the cloud, a solid data foundation in the SAP Business Data Cloud, and processes made visible through process mining.
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
Work@valantic June 10, 2026
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Florian Steinwendtner is Head of SAP Cloud Advisory and leads the logistics team at valantic in Austria. In this interview, he talks about his extraordinary path from landscape gardener to SAP consultant, his enthusiasm for SAP Cloud ERP, and how he is helping to drive valantic's SAP Cloud Powerhouse forward.
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Artificial Intelligence June 9, 2026
SAP Sapphire 2026 – the way into the Autonomous Enterprise
SAP Sapphire 2026 marks the mindshift from assistant to agent: In the Autonomous Enterprise, Joule Assistants orchestrate networked agents that perform routine work independently across SAP and non-SAP systems. They are based on Joule Work and Joule Studio, the SAP Business Data Cloud and the Business AI Platform - provided that the data, cloud setup and culture are in sync.
SAP Sapphire 2026 – the way into the Autonomous EnterpriseDon't miss a thing.
Subscribe to our latest blog articles.

")