Highlight

Successful together – our valantic Team.
Meet the people who bring passion and accountability to driving success at valantic.
Get to know usJune 24, 2025

We reported on the latest updates to SAP Datasphere back in May. If you missed our last blog post, you can read it here: May blog post. The current updates focus in particular on data integration, but there are also exciting innovations in data modeling, the data marketplace, data catalog, and administration. On the one hand, SAP is improving the seamless connection within its range of products and to external suppliers. On the other hand, the management and monitoring of various resources will be enhanced to ensure a continuous workflow.
Data modeling is a central part of SAP Datasphere, so regular updates introduce new features for the models and extend existing features. With the latest extension, the filter variables of the analysis model can specify multiple values at the same time. This allows several value ranges to be defined for the range filter type and makes work more efficient.
Working with large data files in the object store can require many resources and cause performance problems. Accordingly, adjustments were made to the table editor for local tables (file). Default sorting and filtering has been disabled. A filter cannot be added to an action when searching and replacing; the replacement is done in the entire data set. Data previews are now implemented with Apache Spark resources. After its introduction, the new object store will still be optimized as soon as problems become apparent, which improves performance right away and makes it more attractive to use.
Partitioning local table data can help prevent high memory spikes and effectively eliminate issues such as out-of-memory errors. This way, for example, a table can be partitioned using a column, such as the year. However, the partitions may contain uneven amounts of data.
The new hash partitioning feature was introduced to address this issue. This method ensures that all partitions contain an even amount of data. One or more columns can be selected as the basis. This enables efficient and even data distribution without requiring a comprehensive view of the entire data set, thus optimally distributing storage requirements.
Reliable management and monitoring of required storage resources is essential to ensure smooth and efficient use of SAP Datasphere. SAP addresses this need with targeted expansions on different levels to ensure that everything works without disruption.
If your system experiences an error while persisting due to insufficient memory, SAP Datasphere reports an out-of-memory error. However, the cause of this error is not always immediately apparent, as various factors may be responsible for it. Thanks to a recent change, the task log messages now direct users to SAP’s advanced documentation, which provides detailed explanations of possible error sources.
A common trigger for out-of-memory errors is the great complexity of a view. In such cases, you can either increase the available memory or use the View Analyzer to optimize the model and reduce the view’s storage requirements. The number of concurrent tasks can also cause this error. The system monitor can be used to adjust workload distribution, such as transformation flows or task chains. If you want to avoid this error from the start, the appropriate documentation is available: SAP Help.
The View Analyzer has been extended to include all entities from other spaces. This allows detection and resolution of potential sources of error or memory spikes early before they affect workflow. At the same time, it’s easier to analyze and trace the causes of an error.
In addition to optimizing storage management during persistence, monitoring of file storage for local tables in the object store has also been extended. The monitor now provides a detailed overview of the number of active data records, the file memory of the active data records, the file memory of previous data records, and the total file memory for tables, including administrative information. This enables you to detect early on whether additional storage space will be required in the object store. The comparison of previous and active data also enables a better assessment of whether storage expansion is required. These improvements allow preventive planning to effectively prevent potential disruptions or system disruptions.
Regardless of storage management and file storage monitoring, connectivity to Confluent-Kafka sources has been introduced in the area of data integration. To transfer Kafka messages from Confluent using replication flows, it is necessary to link the messages to a fixed schema. These schemas serve as source containers and are provided in the “schema registry context” of replication. Once included, you can define the activity code and primary keys. This extension demonstrates how SAP is continually expanding its ability to connect Datasphere to external vendors to meet its customers’ diverse needs.
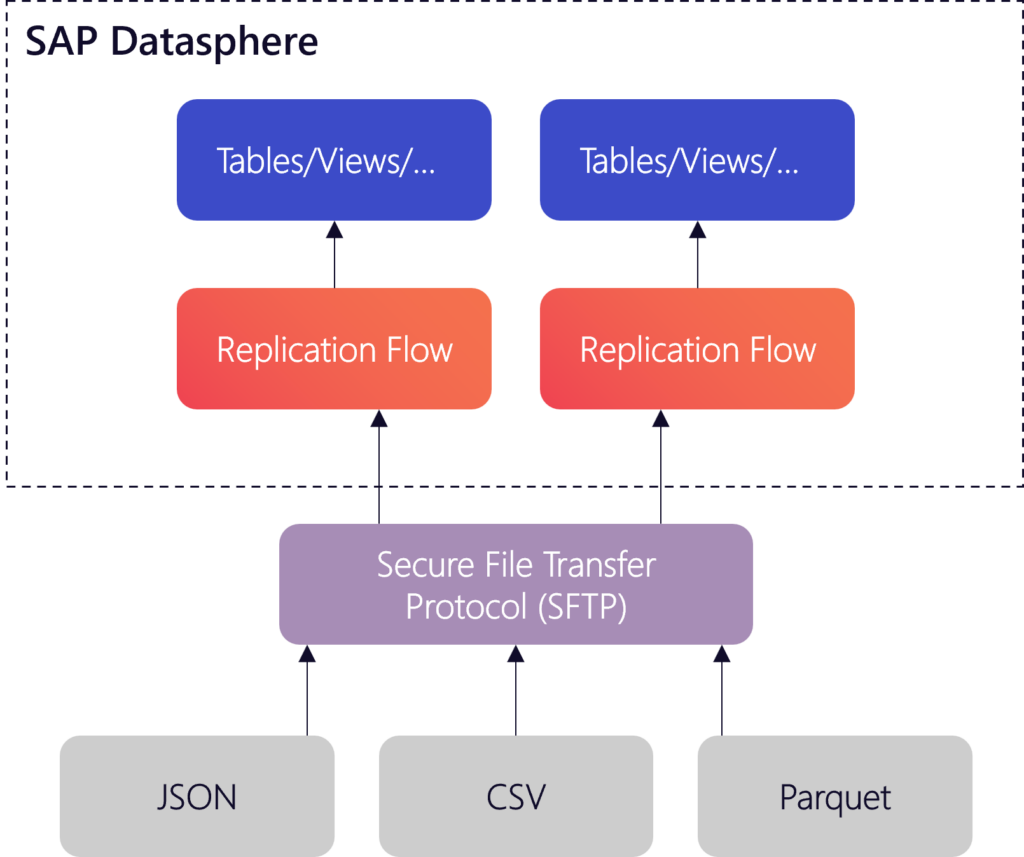
In addition, further updates have improved replication flows. It is now possible to define the Secure File Transfer Protocol (SFTP) as the destination for replication flows. SFTP is a widely used and secure transfer protocol that allows various file formats, such as JSON, CSV, and Parquet, to be integrated directly into SAP Datasphere or imported. Specific settings can be made for the respective formats, such as the definition of a separator for CSV files. This extension not only improves the connectivity of SAP Datasphere, but it also automates repetitive manual processes, such as importing files.
Another new feature has been introduced for replication flows, one that allows source objects to be used in multiple replication flows. This option enables flexible and versatile use of the same source objects, which enables improved organization of different reuses and the creation of a clearer structure.
The integration of data products into the data marketplace has also been optimized. If an SAP Datasphere tenant and an SAP Databricks tenant are part of an SAP Business Data Cloud formation, data products can be deployed. Data delivery is automatic via an integrated delivery, the delivery mode is set to Delta share, and the contract type to unlimited. These settings cannot be changed. Deploying data products for SAP Databricks enables custom-built data packages to be deployed for further processing, for example with artificial intelligence, and updated at any time, without the need to manually import many individual tables. On this basis, forecasts or analyses can be created continuously with defined data. The maintenance of the data is organized centrally.
The management of data products has also been extended. Data products can now be installed for users of the SAP Datasphere command line interface. This allows data products to be rolled out to any number of users without having to use the web interface or make manual assignments. This feature is particularly useful when a data product has proven itself in the development tenant and is now to be established in the productive tenant.
A major innovation for installed data products has been introduced in the data catalog. It is now possible to call up the familiar “analysis of effects and origin” chart. This chart allows you to trace the causes of errors when changes are made to the sources used by the data product or when the data product is initially created. It can also be used to understand the effects of changes on dependent objects.
In addition, there are also marketplace data products in the Data Products collection. This standardizes the process of searching and accessing data products in the catalog. Along with customization of the layout of the Catalog Monitoring page, the user experience is enhanced noticeably. These improvements not only make it easier to get started working with data products, but also to manage them in general.
As an additional optimization of the data catalog, the integration of SAP Datasphere systems with SAP BW-Bridge was refined. A synchronization schedule for the source systems can now be created for the extraction of metadata. This ensures that SAP Datasphere objects are up to date without manual intervention.
In the area of administration, the resource management possibilities have been enhanced. A key innovation is the Capacity Dashboard, which provides an overview of the capacity units consumed. The dashboard provides an overview and CSV export of the capacity units used daily and monthly. It shows how many resources in which space are used by the individual objects and at what intervals they were used. Based on this data, the available resources can be distributed in a targeted and optimized manner. If there is a permanent surplus, it is also possible to adjust resources or analyze individual tasks and, adjust them if necessary.
Another innovation concerns the elastic computing power nodes, especially for users of open-SQL schema tables and HDI container tables. These nodes provide flexible resource utilization for replicating perspectives, analysis models, and analytical data set views. Utilization has now been extended to open SQL schema tables and HDI container tables, significantly extending the capabilities of the computing power nodes. These can be controlled both manually and on a schedule, allowing for even more flexible and efficient use.
Continued enhancement of integration capabilities and optimization of resource management play an essential role in establishing SAP Datasphere as a central data warehouse. In this context, SAP constantly expands the options available to meet its customers’ diverse needs. This makes data modeling even more versatile, while ensuring control of the resources needed.
The SAP Road Map Explorer provides an overview of the upcoming developments. The planned quarterly updates and ideas that continue to shape the quality of SAP Datasphere are also presented here.
valantic will be pleased to assist you with support or any questions you might have about SAP Datasphere.
")
SAP Analytics August 29, 2025
What’s new in SAP Datasphere in August 2025
SAP Datasphere is constantly being improved and expanded. This August update brings major enhancements to SAP Datasphere, focusing on smarter data modeling, expanded integration options, and streamlined administration.
What’s new in SAP Datasphere in August 2025
SAP Services May 27, 2025
What’s New in SAP Datasphere (April 2025)
SAP Datasphere is continuously evolving through ongoing improvements and enhancements. In April 2025, the focus is on data modeling and data integration as well as on innovations in the area of file space in object memory. This blog post is a summary of the most exciting innovations that have been released since mid-March 2025.
What’s New in SAP Datasphere (April 2025)")
SAP Services May 21, 2025
What’s New in SAP Datasphere (March 2025)
SAP Datasphere is continuously evolving through ongoing improvements and enhancements. In this update, we take a closer look at the most recent developments and new features of March 2025.
What’s New in SAP Datasphere (March 2025)Don't miss a thing.
Subscribe to our latest blog articles.
