Highlight

Gemeinsam erfolgreich – unser valantic Team.
Lernen Sie die Menschen kennen, die mit Leidenschaft und Verantwortung bei valantic Großes bewegen.
Mehr über uns erfahren24. Juni 2025

Bereits im Mai haben wir über die neuesten Updates der SAP Datasphere berichtet. Wenn Sie unseren letzten Blogbeitrag verpasst haben, können Sie ihn hier nachlesen: Blogpost Mai. Die aktuellen Updates konzentrieren sich vor allem auf die Datenintegration. Doch gibt es auch spannende Neuerungen in den Bereichen Datenmodellierung, Datenmarktplatz, Datenkatalog und Administration. SAP verbessert einerseits die nahtlose Anbindung innerhalb ihrer Produktlandschaft sowie zu externen Anbietern. Andererseits wird die Verwaltung und Überwachung verschiedener Ressourcen weiter ausgebaut, um einen ununterbrochenen Arbeitsfluss zu gewährleisten.
Die Datenmodellierung ist ein zentraler Bestandteil der SAP Datasphere und daher werden mit den regelmäßigen Updates, neue Funktionen für die Modelle eingeführt und bereits bestehende Funktionen erweitert. Die Filtervariablen des Analysemodells erhalten durch die neuste Erweiterung, die Möglichkeit mehrere Werte gleichzeitig anzugeben. Für den Filtertyp Bereich können dadurch mehrere Wertebereiche definiert werden. Dies unterstützt eine effiziente Arbeitsweise.
Die Arbeit mit großen Datendateien im Objektspeicher kann viele Ressourcen erfordern und zu Performanceprobleme führen. Dementsprechend wurden Anpassungen am Tabelleneditor der lokalen Tabellen (Datei) vorgenommen. Die Standardsortierung und – filterung wurde deaktiviert. Beim Suchen und Ersetzen kann einer Aktion kein Filter mehr hinzufügt werden. Die Ersetzung geschieht im gesamten Datensatz. Die Datenvorschau wird nach den Neuerungen mit Apache-Spark-Ressourcen umgesetzt. Der neue Objektspeicher erhält nach seiner Einführung weiterhin Optimierungen, sobald eventuelle Probleme auffallen sollten. Dadurch wird direkt die Performance verbessert und die Nutzung attraktiver gestaltet.
Die Partitionierung lokaler Tabellendaten kann dabei helfen, hohe Speicherspitzen zu vermeiden und Probleme wie „Out-of-Memory“-Fehler effektiv abzuwenden. So lässt sich beispielsweise eine Tabelle anhand einer Spalte, wie der Jahreszahl, partitionieren. Dabei kann es jedoch vorkommen, dass die Partitionen ungleichmäßig große Datenmengen enthalten.
Um diesem Problem entgegenzuwirken, wurde die neue Funktion der Hash-Partitionierung eingeführt. Diese Methode gewährleistet, dass alle Partitionen eine gleichmäßige Datenmenge enthalten. Hierfür können eine oder mehrere Spalten als Grundlage gewählt werden. Dies ermöglicht eine effiziente und gleichmäßige Aufteilung der Daten, ohne dass zuvor eine umfassende Übersicht über den gesamten Datensatz erforderlich ist, wodurch der Speicherbedarf optimal verteilt wird.
Für eine reibungslose und effiziente Nutzung der SAP Datasphere ist eine zuverlässige Verwaltung und Überwachung der erforderlichen Speicherressourcen essenziell. Diesem Bedarf begegnet SAP durch gezielte Erweiterungen auf unterschiedlichen Ebenen, um eine unterbrechungsfreie Arbeitsweise zu gewährleisten.
Falls in Ihrem System ein Fehler beim Persistieren aufgrund von unzureichendem Speicher auftritt, meldet die SAP Datasphere einen „Out-of-Memory“-Fehler. Die Ursache dieses Fehlers ist jedoch nicht immer sofort ersichtlich, da verschiedene Faktoren dafür verantwortlich sein können. Dank einer kürzlich eingeführten Änderung leiten die Aufgabenprotokollmeldungen nun direkt zur erweiterten Dokumentation von SAP weiter, die detaillierte Erklärungen zu möglichen Fehlerquellen bietet.
Ein häufiger Auslöser für „Out-of-Memory“-Fehler ist die hohe Komplexität einer View. In solchen Fällen können Sie entweder den verfügbaren Speicher erhöhen oder den View-Analyzer verwenden, um das Modell zu optimieren und den Speicherbedarf der View zu reduzieren. Darüber hinaus kann auch die Anzahl gleichzeitig ausgeführter Aufgaben zu diesem Fehler führen. Mithilfe des Systemmonitors lässt sich die Workload-Verteilung, beispielsweise bei Transformationsflüssen oder Aufgabenketten, anpassen. Wenn Sie diesen Fehler präventiv vermeiden möchten, steht Ihnen die entsprechende Dokumentation zur Verfügung: SAP Help.
Der View Analyzer wurde erweitert, sodass nun alle Entitäten aus anderen Spaces berücksichtigt werden. Dadurch können potenzielle Fehlerquellen oder Speicherspitzen frühzeitig erkannt und behoben werden, bevor sie den Arbeitsfluss beeinträchtigen. Gleichzeitig können die Ursachen eines Fehlers besser analysiert und zurückverfolgt werden.
Zusätzlich zur Optimierung der Speicherverwaltung beim Persistieren wurde auch die Überwachung des Dateispeichers für lokale Tabellen im Objektspeicher erweitert. Der Monitor bietet nun eine detaillierte Übersicht über die Anzahl der aktiven Datensätze, den Dateispeicher der aktiven Datensätze, den Dateispeicher vorheriger Datensätze sowie den gesamten Dateispeicher für Tabellen inklusive Verwaltungsinformationen. Damit lässt sich frühzeitig erkennen, ob zusätzlicher Speicherplatz im Objektspeicher benötigt wird. Zudem ermöglicht der Vergleich von vorherigen und aktiven Daten eine bessere Einschätzung, ob eine Speichererweiterung notwendig wird. Diese Verbesserungen erlauben eine präventive Planung, um potenzielle Störungen oder Systemunterbrechungen effektiv zu vermeiden.
Unabhängig von Speicherverwaltung und Dateispeicherüberwachung wurde die Anbindung an Confluent-Kafka-Quellen im Bereich der Datenintegration eingeführt. Um Kafka-Nachrichten aus Confluent mithilfe von Replikationsflüssen zu übertragen, ist eine Verknüpfung der Nachrichten mit einem festen Schema erforderlich. Diese Schemata dienen als Quellcontainer und werden im „Schema-Registry-Context“ der Replikation bereitgestellt. Nach der Einbindung können Vorgangscode und Primärschlüssel definiert werden. Diese Erweiterung verdeutlicht, wie SAP die Anbindung ihrer Datasphere an externe Anbieter kontinuierlich ausbaut, um den vielfältigen Anforderungen ihrer Kunden gerecht zu werden.
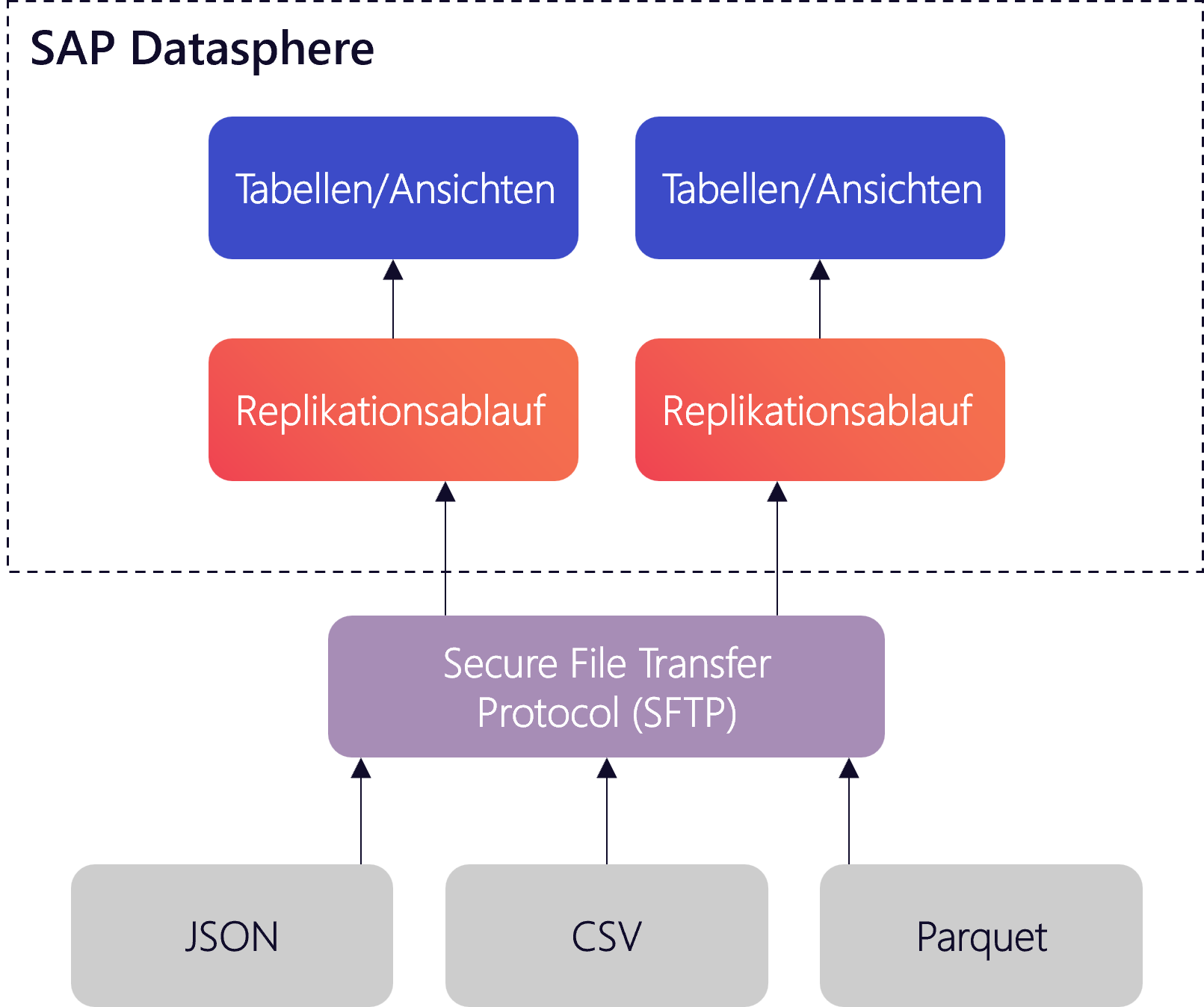
Zusätzlich wurden die Replikationsflüsse durch weitere Updates verbessert. Es ist nun möglich, das Secure File Transfer Protocol (SFTP) als Ziel für Replikationsflüsse zu definieren. SFTP ist ein weitverbreitetes und sicheres Übertragungsprotokoll, das es erlaubt, verschiedene Dateiformate wie JSON, CSV und Parquet direkt in die SAP Datasphere zu integrieren bzw. nun zu importieren. Dabei können für die jeweiligen Formate spezifische Einstellungen vorgenommen werden, etwa die Definition eines Trennzeichens bei CSV-Dateien. Diese Erweiterung verbessert nicht nur die Anbindungsmöglichkeiten der SAP Datasphere, sondern automatisiert auch wiederkehrende manuelle Prozesse, wie das Importieren von Dateien.
Darüber hinaus wurde für Replikationsflüsse eine neue Funktion eingeführt, die es erlaubt, Quellobjekte in mehreren Replikationsflüssen zu verwenden. Diese Option ermöglicht eine flexible und vielseitige Nutzung derselben Quellobjekte, wodurch unterschiedliche Weiterverwendungen besser organisiert und eine übersichtlichere Struktur geschaffen werden können.
Die Integration von Datenprodukten im Datenmarktplatz wurde ebenfalls optimiert. Wenn ein SAP Datasphere-Tenant und ein SAP Databricks-Tenant Teil einer SAP Business Data-Cloud-Formation sind, können Datenprodukte bereitgestellt werden. Die Datenlieferung erfolgt automatisch über eine integrierte Lieferung, der Liefermodus wird auf Delta-Anteil und die Vertragsart auf unbeschränkt gesetzt. Diese Einstellungen sind unveränderlich. Durch die Bereitstellung von Datenprodukten für SAP Databricks können speziell zusammengestellte Datenpakete für die Weiterverarbeitung, beispielsweise durch künstliche Intelligenz, bereitgestellt und jederzeit aktualisiert werden, ohne dass ein manueller Import vieler einzelner Tabellen erforderlich ist. Auf dieser Grundlage können kontinuierlich Vorhersagen oder Analysen mit definierten Daten durchgeführt werden. Die Pflege der Daten ist dabei zentral organisiert.
Weiterhin wurde die Verwaltung von Datenprodukten erweitert. Datenprodukte können nun über die Befehlszeilenschnittstelle der SAP Datasphere für Benutzer:innen installiert werden. Dies ermöglicht das Ausrollen von Datenprodukten für eine beliebige Anzahl von Benutzer:innen, ohne auf die Web-Oberfläche zurückgreifen oder manuelle Zuweisungen tätigen zu müssen. Diese Funktion ist besonders nützlich, wenn ein Datenprodukt sich im Entwicklungs-Tenant bewährt hat und nun im produktiven Tenant etabliert, werden soll.
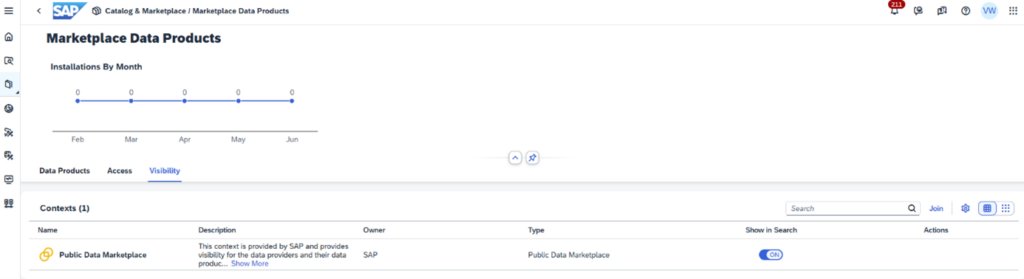
Im Datenkatalog wurde eine bedeutende Neuerung für installierte Datenprodukte eingeführt. Es ist nun möglich, das bekannte Diagramm „Analyse der Auswirkungen und der Herkunft“ aufzurufen. Dieses Diagramm ermöglicht es, bei Änderungen an den Quellen, die vom Datenprodukt verwendet werden, oder bei der initialen Erstellung die Ursachen von Fehlern zurückzuverfolgen. Ebenso lassen sich damit die Auswirkungen von Änderungen auf abhängige Objekte nachvollziehen. Zusätzlich werden durch das neueste Update Marktplatz-Datenprodukte in der Sammlung „Datenprodukte“ angezeigt. Damit wird der Prozess der Suche und des Zugriffs auf Datenprodukte im Katalog standardisiert. Zusammen mit einer Anpassung des Layouts der Katalogüberwachungsseite wird die Benutzerfreundlichkeit spürbar erhöht. Diese Verbesserungen erleichtern nicht nur den Einstieg in die Arbeit mit Datenprodukten, sondern auch deren allgemeine Verwaltung.
Als zusätzliche Optimierung des Datenkatalogs wurde die Integration von SAP Datasphere-Systemen mit SAP BW-Bridge verfeinert. Für die Extraktion von Metadaten kann nun ein Synchronisierungszeitplan für die Quellsysteme erstellt werden. Dies gewährleistet die Aktualität der SAP Datasphere-Objekte, ohne dass ein manuelles Eingreifen erforderlich ist.
Administration
Im Bereich der Administration wurden die Möglichkeiten zur Verwaltung von Ressourcen weiterentwickelt. Eine zentrale Neuerung ist das Kapazitäts-Dashboard, das einen Überblick über die verbrauchten Kapazitätseinheiten bietet. Das Dashboard stellt eine Übersicht sowie einen CSV-Export der täglich und monatlich genutzten Kapazitätseinheiten zur Verfügung. Es zeigt an, wie viele Ressourcen in welchem Space von den einzelnen Objekten genutzt werden und in welchen Intervallen diese zum Einsatz kamen. Auf Basis dieser Daten können die verfügbaren Ressourcen gezielt optimiert verteilt werden. Bei dauerhaftem Überschuss besteht zudem die Möglichkeit, Ressourcen anzupassen oder einzelne Aufgaben zu analysieren und gegebenenfalls anzupassen.
Eine weitere Innovation betrifft die elastischen Rechenleistungsknoten, speziell für Nutzer von Open-SQL-Schematabellen und HDI-Container-Tabellen. Diese Knoten ermöglichen eine flexible Ressourcennutzung für die Replikation von Perspektiven, Analysemodellen und Views des Typs „analytisches Datenset“. Die Nutzung wurde nun auf Open-SQL-Schematabellen und HDI-Container-Tabellen ausgeweitet, wodurch die Einsatzmöglichkeiten der Rechenleistungsknoten erheblich erweitert wurden. Diese können sowohl manuell als auch über einen Zeitplan gesteuert werden, was eine noch flexiblere und effizientere Nutzung ermöglicht.
Der fortlaufende Ausbau der Integrationsmöglichkeiten sowie die Optimierung der Ressourcenverwaltung spielen eine essenzielle Rolle, um die SAP Datasphere als zentrales Data-Warehouse zu etablieren. In diesem Zusammenhang erweitert SAP kontinuierlich die verfügbaren Optionen, um den vielfältigen Bedürfnissen seiner Kund:innen gerecht zu werden. Dadurch wird die Datenmodellierung noch vielseitiger gestaltet, während gleichzeitig die Kontrolle über die benötigten Ressourcen sichergestellt bleibt.
Der SAP Road Map Explorer gibt einen Überblick auf die kommenden Entwicklungen. Hier werden quartalsweise die geplanten Updates und Ideen präsentiert, die die Qualität der SAP Datasphere weiterhin gestalten und prägen.

Kontakt
Für Unterstützung oder bei Fragen zu der SAP Datasphere steht valantic Ihnen gerne zur Seite.

Business Analytics 12. November 2025
What’s new in SAP Datasphere in November 2025
Seit dem letzten Blogpost im August gab es viele Erneuerungen in der SAP Datasphere: Mehrere Wellendeployments brachten spannende Innovationen und Optimierungen. Im Fokus stehen diesmal Datenintegration, Administration und Datenmodellierung.
What’s new in SAP Datasphere in November 2025")
SAP Analytics 29. August 2025
What’s new in SAP Datasphere in August 2025
Die SAP Datasphere wird laufend verbessert und erweitert. Das August Update bringt deutliche Verbesserungen für SAP Datasphere mit sich, wobei der Schwerpunkt auf intelligenterer Datenmodellierung, erweiterten Integrationsoptionen und optimierter Verwaltung liegt.
What’s new in SAP Datasphere in August 2025
Uncategorized 16. Mai 2025
What’s new in SAP Datasphere (Mai 2025)
Die SAP Datasphere wird laufend verbessert und erweitert. Im Zuge dessen schauen wir auf die neusten Änderungen im Mai 2025.
What’s new in SAP Datasphere (Mai 2025)Nichts verpassen.
Blogartikel abonnieren.
