Highlight

Gemeinsam erfolgreich – unser valantic Team.
Lernen Sie die Menschen kennen, die mit Leidenschaft und Verantwortung bei valantic Großes bewegen.
Mehr über uns erfahrenSeit unserem letzten Blogbeitrag im April, wurde die SAP Datasphere wieder um einige Updates erweitert. Sollten Sie unser letztes What’s New verpasst haben, finden Sie den Beitrag hier: Blogpost. Wir freuen wir uns, Ihnen die neusten Innovationen aus dem Mai 2025 vorzustellen. In diesem Blogpost steht dabei das Analysemodell im Bereich der Datenmodellierung im Vordergrund. Außerdem wird der Datenkatalog und die Datenintegration betrachtet.
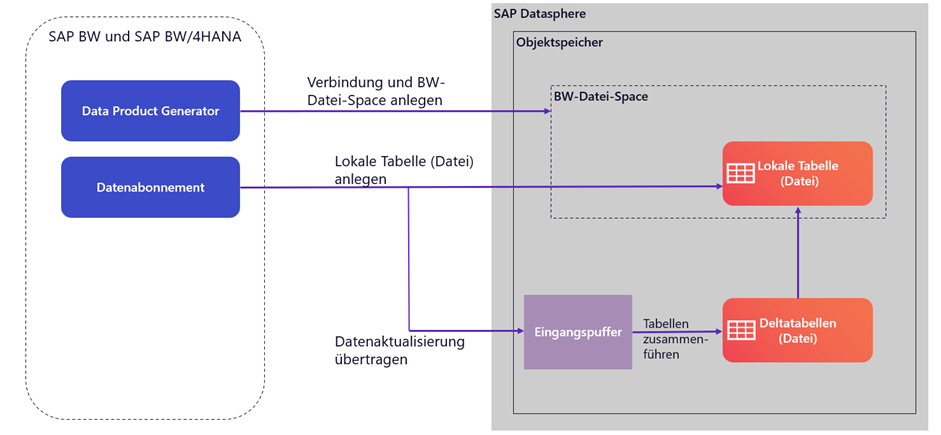
Im Rahmen der letzten Updates stellten wir den Objektspeicher vor. Dieser bietet die Möglichkeit Daten im Push-Verfahren direkt aus einem SAP BW oder SAP BW/4HANA zu erhalten. Wenn die benötigten Daten im Quellsystem enthalten sind, ist es nicht nötig diese per SAP Datasphere einzubinden. Sie können direkt in den Objektspeicher übertragen werden. Hierbei gibt es einige Einschränkungen. Unter anderem können Eigenschaften der vom SAP BW generierten lokalen Tabelle nicht verändert werden. Zudem ist die Delta-Erfassung vorab als aktiviert oder deaktiviert festgelegt und nicht veränderbar. Es werden bei deaktivierter Delta-Erfassung Snapshot-Versionen aufbewahrt.
Neben dem Objektspeicher wurde die Möglichkeiten zur Datenförderation erweitert. Es ist möglich den ABAP-SQL-Service für Remote-Zugriff auf SQL-Ebene für Daten aus ABAP-verwaltenden CDS-View-Entitäten in SAP S/4HANA mit Verbindungstyp SAP ABAP zu nutzen. Der SQL-Zugriff ermöglicht eine spezifischere Vorauswahl an Daten. In diesem Zuge kann auf eine umfangreiche Nachbearbeitung insbesondere bei umfangreichen CDS-Views verzichtet werden. Für den SQL-Zugriff wurde zusätzlich der Abschnitt „Remote-Tabellen“ eingefügt. Dieser beinhaltet die Option „Cloud-Connector“ für Datenflüsse und Replikationsflüsse. Für klassische Remote-Tabellen gibt es die Möglichkeit „Direkt“.
Weitere Innovationen der SAP Datasphere stellen grundlegende und flexible Anpassungen bei neu erstellten Analysemodells bereit. Es lässt sich ein neues Analysemodell aus einem bereits bestehenden Analysemodell kreieren. Dabei werden nützliche Eigenschaften des Analysemodells, wie Assoziationen, Variablen, Datenzugriffskontrollen und weitere integriert. Eine genaue Übersicht finden Sie auf der SAP Dokumentation. Somit lässt sich ohne zusätzlichen Aufwand ein erweitertes oder zusätzliches Reporting erstellen. Zudem wird die Gegenüberstellung von geplanten Änderungen mit dem Status quo zum Vergleich unterstützt.
Eine weitere Neuerung ermöglicht es, die Faktenquelle eines Analysemodells zu ersetzen. Dabei gilt es zu beachten, dass die neue Faktenquelle u. a. dieselben Attribute, Assoziationen, Kennzahlen und Eingabeparameter besitzen muss. Ob die Anpassungen korrekt sind, lässt sich durch eine Validierung überprüfen. Dadurch wird die Anzahl an späteren Anpassungen in den darüberliegenden Schichten, wie dem Reporting-Layer reduziert.
Seit dem letzten Update wurden die Validierungsoptionen für semantische Views um eine spannende Funktion erweitert: Die Nutzung des „Fakts“. Bisher konnten Schlüssel bereits auf Eindeutigkeit geprüft und sichergestellt werden, dass keine „NULL“-Werte in den entsprechenden Feldern vorhanden sind. Mit der neuesten Erweiterung kommt nun die Prüfung der referenziellen Integrität hinzu.
Diese Funktion stellt sicher, dass alle Werte in der Fremdschlüsselspalte auch tatsächlich in den zugehörigen Dimensionstabellen existieren. Das bedeutet: Beim Ersetzen eines Fakts oder beim Hinzufügen neuer Dimensionen können potenzielle Fehler direkt erkannt und entsprechende Anpassungen sofort vorgenommen werden. Eine wertvolle Verbesserung, die die Konsistenz und Qualität der Daten in semantischen Views steigert.
Das Update bringt außerdem Neuerungen für die Arbeit mit Kennzahlen im Analysemodell mit sich. Ab sofort lassen sich das Format einer Kennzahl – wie beispielsweise die Anzahl der Dezimalstellen oder die Skalierung – im Abschnitt „Formatierung“ des Editors anpassen.
Zusätzlich wurde eine weitere Funktion eingeführt, die tiefere Einblicke in die Struktur des Analysemodells ermöglicht: Es ist nun möglich, sowohl die Herkunft als auch die Auswirkungen von Kennzahlen direkt im Modell auszuwerten. Diese Erweiterung bietet nicht nur mehr Flexibilität in der Darstellung von Kennzahlen, sondern erleichtert auch die Nachvollziehbarkeit und Optimierung der Analysemodelle.
Mit den neuen Möglichkeiten im Analysemodell bietet SAP nun einen noch flexibleren Umgang mit Änderungen und Erweiterungen der bestehenden Struktur – und das ganz ohne Anpassungen an den Datenquellen oder die Neuerstellung des Modells. Diese Anpassungen können direkt in der SAP Analytics Cloud genutzt werden und vereinfachen somit die Integration und Weiterentwicklung erheblich. Eine der spannendsten Neuerungen ist die Möglichkeit, die Performance einer View mithilfe von Laufzeitmetriken zu analysieren. Im Data Builder können nun zwei Datenbankabfragen direkt ausgeführt werden, um wichtige Kennzahlen wie die Ausführungsdauer, die Anzahl der genutzten Quellen, die Datenzugriffe oder die maximale Speicherauslastung zu ermitteln. Ergänzend dazu kann ein Explain Plan erstellt werden, der den Ressourcenbedarf einer View bereits während der Erstellung aufzeigt.
Diese Performance-Analysen ermöglichen es, den Ressourcenverbrauch gezielt zu optimieren und das Modell individuell anzupassen. Darüber hinaus lassen sich Aktualisierungen im Einklang mit anderen Aufgaben zeitlich abstimmen, um Überlastungen des Systems zu vermeiden – ein klarer Pluspunkt für eine effizientere und stabilere Datenmodellierung.
Wie bereits angekündigt, steht in den kommenden Quartalen der Datenkatalog im Fokus. Der Datenkatalog lässt sich nun spezifischer für einen SAP Datasphere-Space konfigurieren. Falls ein Datenprodukt nicht mehr benötigt wird, lässt sich dieses aus einem Space entfernen. Hierdurch können Ressourcen explizit auf die Spaces neu verteilt und aus nicht benötigten Ressourcen entfernen werden.
Eine weitere Anpassung betrifft ebenfalls den Datenkatalog: Zwei Sammlungen haben neue Namen erhalten. Die Sammlung „SAP Business Data Cloud-Datenprodukte“ wurde in „Datenprodukte“ umbenannt. Gleichzeitig erhielt die „Marktplatz-Datenprodukte“-Sammlung den neuen Namen „Datenprodukte (Marktplatz)“.
Diese Umbenennungen sorgen für mehr Klarheit im Datenkatalog und erleichtern die Orientierung und Zuordnung der verschiedenen Datenprodukte innerhalb der Plattform. Ein kleiner Schritt, um die Benutzerfreundlichkeit weiter zu steigern.
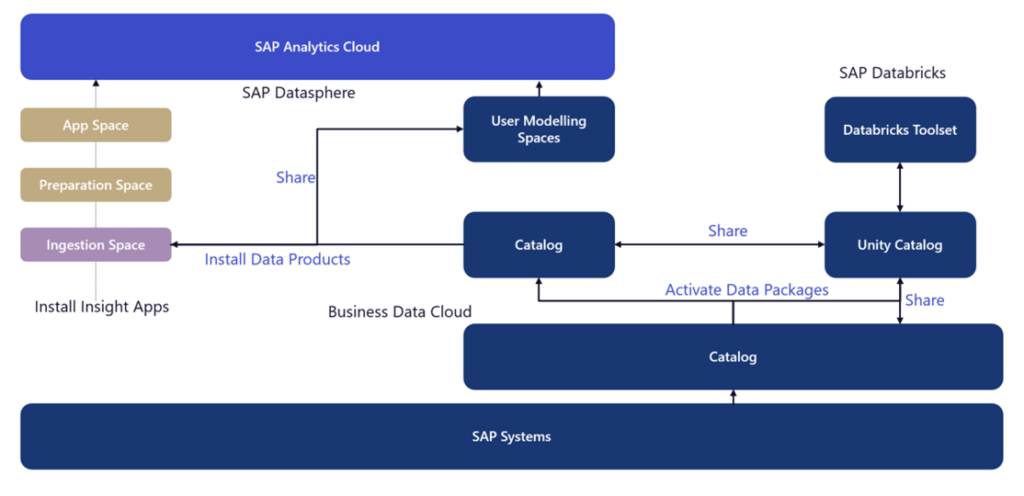
Die Integration von Databricks in die SAP BDC eröffnet Unternehmen neue Möglichkeiten, indem sie wertvolle Einblicke aus großen Datenmengen gewinnen und diese mit KI-gestützten Modellen kombinieren können. Die Metadaten aus dem Unity Catalog aus Databricks sollen zukünftig an den Data Catalog der SAP Datasphere geteilt werden können.
Im Bereich der Datenverarbeitung stehen die flexible Anpassung der Datengrundlage und die Optimierung des Ressourcenverbrauchs stets im Mittelpunkt des Interesses. Aus diesem Grund legt SAP großen Wert darauf, kontinuierliche Updates bereitzustellen, die nicht nur eine umfangreiche und leistungsfähige Datenmodellierung ermöglichen, sondern auch eine bessere Übersicht über die benötigten Systemressourcen bieten. Diese Fortschritte sind entscheidend, um den ständig wachsenden Anforderungen an die Datenverarbeitung gerecht zu werden und eine effiziente Nutzung der vorhandenen Technologien sicherzustellen.
Wer neugierig auf zukünftige Innovationen ist, kann im SAP Road Map Explorer einen Blick auf die kommenden Entwicklungen werfen. Hier werden regelmäßig Pläne und Ideen präsentiert, die die Qualität der SAP Datasphere weiter gestalten und prägen.
Für Unterstützung oder bei Fragen zu der SAP Datasphere steht valantic Ihnen gerne zur Seite.

Künstliche Intelligenz 22. Juli 2026
Interview: Wie gelingt der strukturierte Einstieg in Agentic AI?
Agentic AI schafft nur dann langfristigen Wert, wenn KI-Anwendungen nahtlos in Prozesse eingebunden und mit klaren Kontrollmechanismen versehen sind. Wie ein AI Workshop beim strukturierten Einstieg unterstützen kann und Organisationen durch die Entwicklung eines produktionsnahen KI-Agenten erste Erfolge erzielen, hat uns Maria Kern, Digital Experience Architect, beantwortet.
Interview: Wie gelingt der strukturierte Einstieg in Agentic AI?
Customer Experience 16. Juli 2026
Von Segmenten zu persönlicher 1:1 Relevanz: Was Hyperpersonalisierung im Retail bedeutet
Der Retail hat Personalisierung auf der Agenda – bislang aber vor allem als technische Capability. KI verändert gerade einerseits die Erwartungen an personalisierte Erlebnisse, zum anderen die technischen Mittel, um echte 1:1 Relevanz zu bieten. Das macht Hyperpersonalisierung am Ende aus: Persönlichkeit und Kontext, die Vertrauen, Glaubwürdigkeit und Bindung schaffen.
Von Segmenten zu persönlicher 1:1 Relevanz: Was Hyperpersonalisierung im Retail bedeutet
Work@valantic 10. Juni 2026
Florians SAP Karriere: Wie er das Cloud-Business bei valantic in Österreich voranbringt
Florian Steinwendtner ist Head of SAP Cloud Advisory und leitet das Logistik-Team bei valantic in Österreich. Im Interview spricht er über seinen außergewöhnlichen Weg vom Landschaftsgärtner zum SAP-Berater, seine Begeisterung an SAP Cloud ERP und darüber, wie er valantics SAP Cloud Powerhouse mit vorantreibt.
Florians SAP Karriere: Wie er das Cloud-Business bei valantic in Österreich voranbringtNichts verpassen.
Blogartikel abonnieren.

