Highlight

Gemeinsam erfolgreich – unser valantic Team.
Lernen Sie die Menschen kennen, die mit Leidenschaft und Verantwortung bei valantic Großes bewegen.
Mehr über uns erfahren29. August 2025
")
Mittlerweile ist unser letzter Blogpost im Juni schon eine ganze Weile her. Seitdem gab es mehrere Wellendeployments mit aufregenden Innovationen und nützlichen Anpassungen. Die, nach unserer Meinung, wichtigsten Updates würden wir Ihnen gerne im Anschluss zur Sommerpause vorstellen. Die Datenmodellierung steht neben der Datenintegration mit neuen Anbindungen zur SAP Datasphere dieses Mal im Mittelpunkt. Doch auch der Datenkatalog und Administration erhalten interessante neue Funktionen und Anpassungen.
Neben den Optionen zur Verarbeitung bei der Datenmodellierung spielt auch die Korrektheit eine entscheidende Rolle, um am Ende ein aussagekräftiges Modell zu erhalten. Dafür wurde die Datenvalidierung von Hierarchien erweitert. Diese umfasst nun eine Prüfung auf fehlende Hierarchieknoten. Jede in der Hierarchie mit Verzeichnis definierte Hierarchie muss Knoten für alle entsprechenden Fremdschlüsselwerte bereitstellen, die in Datensätzen im Fakt verwendet werden.
Dies bedeutet, wenn zum Beispiel Datensätze im Fakt den Währungsschlüssel „USD“ besitzen, aber dieser nicht als Hierarchieknoten vorhanden ist, sind sämtliche Daten, die „USD“ zugewiesen sind, nicht in der Aggregation unter der Hierarchie vorhanden. Diese fehlenden Knoten können jetzt identifiziert und exportiert werden.
Anschließend kann man manuell die fehlenden Knoten nachpflegen oder alle fehlenden Knoten unter dem Knoten „MISSING“ zusammenfassen, um die Daten nicht in der Ansicht zu verlieren.
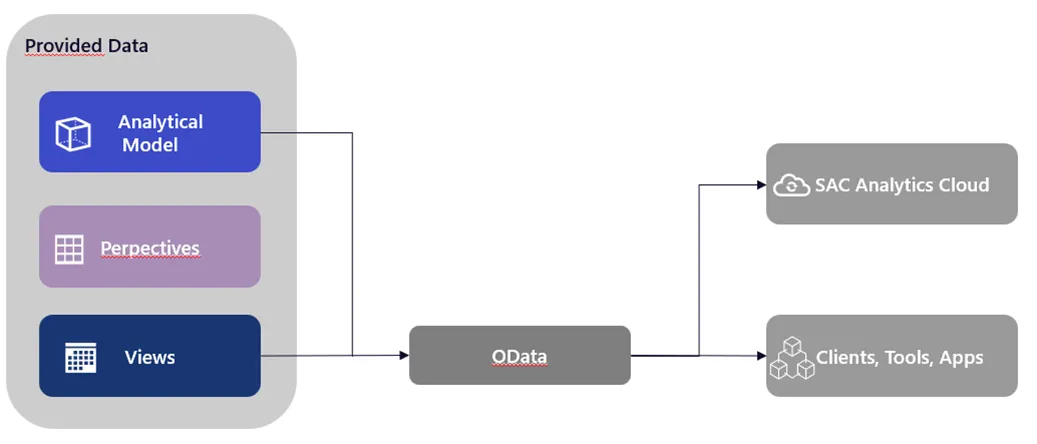
Die Erstellung von OData-Service-Routen wurde für Assets in der Datenmodellierung deutlich vereinfacht, da es nun möglich ist, eine OData-Anforderung generieren zu lassen. Wenn man z.B. grade ein neues analytisches Modell erstellt hat, kann man durch die Generierung diese Version direkt einem anderen Nutzer:innen zukommen lassen. Das ermöglicht ein einfaches Teilen von Objekten, um diese beispielsweise direkt in der SAP SAC zu testen.
Zusätzlich zur Generierung von OData-Service-Routen wurde für die OData-Consumption-API die $batch -Syntax eingeführt, da Datenkonsumenten, wie SAP Build oder SAP-Fiora-Elements-Apps, ausschließlich mittels OData-Syntax $batch genutzt werden können. Dabei gilt es zu beachten, dass der Inhalt des Texts einer $batch-Anforderung auf eine einzige GET-Anforderung limitiert ist. Die SAP zeigt so, wie sie stetig an einer besseren Verknüpfung der eigenen Produkte auf verschiedenen Ebenen arbeitet.
Im Zuge der letzten Neuerungen sind abgeleitete Variablen auf Filtervariablen und Variablen für eingeschränkte Kennzahlen verfügbar gemacht worden. Damit können diese Variablentypen von den Vorteilen der abgeleiteten Variablen profitieren. Dabei wird der Wert der Variable über eine Lookup-Entität vom System abgerufen. Als greifbares Beispiel kann man hier eine Land-/Währung-Abhängigkeit nehmen. Wenn nun ein Land angegeben wird, kann automatisch die Währung bestimmt werden. Weitere Vorteile sind die Wiederverwendbarkeit der Lookup-Entitäten in mehrere Analysemodellen und die zentrale Pflege der Daten.
Im Bereich der Datenmodellierung optimiert die SAP weiter den Objektspeicher. Bezüglich der Transformationsflüsse im Datei-Speicher des Objektspeichers kann nun eine inkrementelle Aggregation ausgewählt werden. Wenn die Datenladevorgänge bereits inkrementell sind, können so aggregierte Ergebnisse effizient gepflegt werde. Den gesamten Ladevorgang abzuwarten oder die gesamte lokale Tabelle (Datei) zu analysieren, kann so umgangen werden.
Dazu kommt noch eine weitere Anpassung der Transformationsflüsse. Die Drag&Drop-Funktion steht Ihnen jetzt im Datei-Speicher zur Verfügung, wie man es schon aus der SAP Datasphere gewohnt ist. Die Handhabung von Datenverarbeitung im Objektspeicher und in klassischen Spaces der SAP Datasphere werden so vereinheitlicht, was den Einstieg und die weitere Nutzung erleichtert.
Die Datentypen für lokale Tabellen (Datei) im Objektspeicher wurden ebenfalls, um DateTime, hana.BINARY und hana.TINYINT, erweitert. Diese können anschließend für die Datenmodellierung und Partitionierung genutzt werden, was insbesondere bei DateTime eine willkommene Erweiterung des Objektspeichers ist.
Eine zusätzliche Anmerkung am Ende für alle unter Ihnen die auch gerne auf Python- oder SQL-Scripting zurückgreifen statt grafischer Views. Der Editor in SQL-Views stellt nun Syntaxfehler in SQL-Quellen im Meldungsbereich mit Zeilennummern gekennzeichnet dar oder hebt die fehlhaften Zeilen hervor. Korrekturen an der richtigen Stelle lassen sich so schneller umsetzten und führt zu einem besseren Workflow. Bei Python ist noch anzumerken, dass die Version 3.11 ab jetzt verfügbar ist und 3.9 abgekündigt wurde.
Für eine flexible und ganzheitliche Datenintegration sind eine große Anzahl an verschiedenen Quellsystemen mit Konfigurationsmöglichkeiten entscheidend. Dementsprechend geht es in diesen Blogpost als Erstes, um den Replikationsfluss und dessen neuste Updates.
Es ist seit den Neuerungen möglich direkt einen SQL- oder Script-View in einem Replikationsfluss als Quelle einzubinden. Der SQL- und Script-View als Quelle ist für SAP HANA Cloud, SAP HANA On-Premise und SAP Datasphere verfügbar. Es gibt Einschränkungen bei der Nutzung, da ausschließlich der Ladetyp „Nur Initial“ verwendet werden kann, der View darf keine Parameter enthalten und es muss ein Primärschlüssel definiert werden. Durch die Neuerung ist ein direkter Zugang ohne weitere Verarbeitungsschritte gegeben, was neben der Entwicklung grade das Testen von neuen Ideen deutlich vereinfacht.
Letzten Blogpost berichteten wir bereits über den SFTP als neue Möglichkeit für die Integration von Daten in der SAP Datasphere. Seit diesen Neuerungen steht der SFTP als Quelle für Replikationsflüsse zur Verfügung. Wie auch bei den SFTP als direkte Quelle, ist der Ladetyp „Nur Initial“ die einzige Option in einem Replikationsfluss. Durch die Quelleinstellungen lassen sich Performance und Funktionen nach Ihren Anforderungen anpassen. Die maximale Anzahl an Partitionen gibt zum Beispiel die Möglichkeit, die genutzten Ressourcen zu bestimmen, um etwaige Überlastungen des Systems zu vermeiden. Die Option „Unterordner einschließen“ kann eine größere Anzahl an Daten laden, da Unterordner rekursiv durchlaufen werden. Für eine genaue Übersicht der Funktionalitäten, hat die SAP hier eine Übersicht bereitgestellt: SFTP und Replikationsfluss. Hieran erkennt man, dass die SAP stetig die Szenarien ausbaut, in denen es eine native Lösung für Probleme bietet. Der automatisierte Import von CSV-Dateien über SFTP ersetzt hierbei kein S4/Hana oder ähnliche Quellsysteme, aber kann zum Beispiel eine Übergangslösung sein, bis eine vollständige Migration abgeschlossen ist oder wenn einzelne CSV-Dateien als Basis notwendig sind.
Um die Performance von Replikationsflüssen zu verbessern, wurde die RFC-Schnellserialisierung in der SAP-S/4HANA-Cloud ermöglicht. Dies kann insbesondere bei großen Datenmengen einen Vorteil bringen. Die Schnellserialisierung ist bei neu angelegten Replikationsflüssen automatisch eingestellt. Für bereits Vorhandene muss dies dagegen manuell nachgeholt werden.
Als weitere Neuerung für die Replikationsflüsse kommt die Option hinzu, den Ladetyp „Nur Delta“ einzustellen. Dadurch kann in bestimmten Geschäftsfällen die Erstdatenübernahme ausgelassen werden. Der Speicherbedarf wird so reduziert und es lassen sich ebenso Tabellen erzeugen, die einen Vergleich zwischen Erstdaten und den Delta-Änderungen ermöglichen.
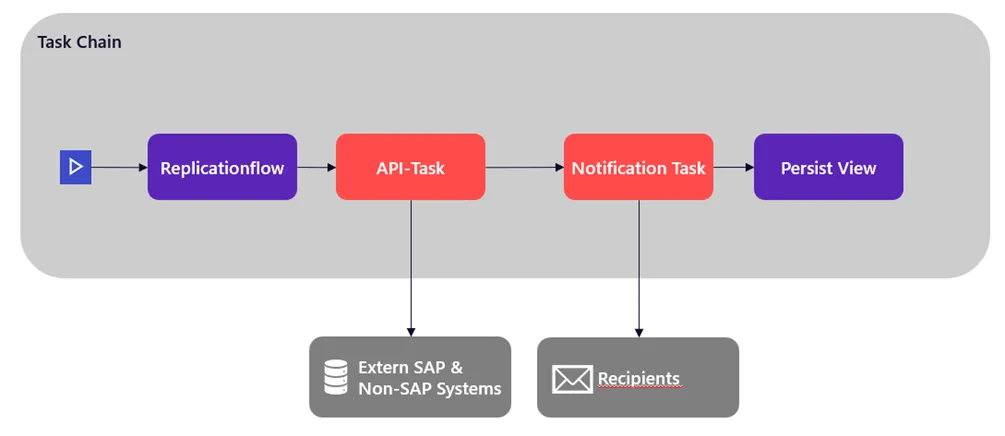
Neben den Replikationsflüssen haben die Aufgabenketten mehrere Updates erhalten. Als kleinere Änderung, die mich sehr freut, würde ich hier gerne die neue Layout-Option aufzeigen. Es ist jetzt möglich, die Aufgabenketten anstatt von oben nach unten (Standard), auch von links nach rechts anzuzeigen. Dies ist eine persönliche Präferenz, die eventuell einige andere Anwender teilen.
Hinzu kommt bei der Aufgabenkette die Innovation als Aufgabe auf externe Systeme mit REST-basierte API-Calls zuzugreifen. Dafür muss zunächst eine Verbindung vom Typ „Generisches HTTP“ angelegt werden. Hier kann zwischen den Authentifizierungstypen „Keine Authentifizierung“, „Benutzername und Kennwort“ oder „OAuth2“ mit Client-Anmeldeinformationen oder Benutzername und Kennwort gewählt werden. Hinzukommen verschiedenen Konfigurationsmöglichkeiten, wie zum Beispiel ob ein On-Premise-System oder eine Cloud-Variante handelt oder ob das Cloud-System einen Standort hat oder virtuell ist. Die API-Aufrufe sind dabei auf die POST- und GET-Methode beschränkt. Hierdurch wird eine Kommunikation zu externen Systemen geschaffen. Dies eröffnet beispielsweise die unkomplizierte Möglichkeit einen Status einer bestimmten Aufgabenkette zu melden, ein Zwischenergebnis abzuspeichern oder auch ein Protokoll an externer Stelle zu erstellen. Bei asynchronen Requests kann im Nachhinein mittels der GET-Methode der Status überprüft werden.
Als weitere Neuerung zu den Aufgabenketten, lassen sich nun Benachrichtigungsaufgaben integrieren. Diese können an beliebiger Stelle eingebaut werden und die entsprechende Nachricht definiert werden. Die Empfängerliste ist dabei dieselbe, die auch bei der Aufgabenkette an sich hinterlegt ist. Falls ein Zwischenschritt fehlschlägt, bekommt der Verantwortliche direkt eine konkrete Nachricht. Genauso können Anwender, die nur auf den Abschluss eines einzelnen Elements warten, direkt benachrichtigt werden und müssen nicht auf den gesamten Abschluss der Aufgabenkette warten.
Unabhängig der Replikationsflüssen und Aufgabenketten gibt es noch weitere Anpassungen und Updates in verschiedenen Bereichen. Zunächst wurde die Filteroptionen zum Löschen von Daten um „Date“ und „DateTime“ erweitert. Das ermöglicht, zum Beispiel, dass Löschen von fehlerhaften Daten in einem gewissen Zeitraum oder alle Daten bis/nach einem bestimmten Zeitpunkt. Dies kann für unterschiedlichste Szenarien, die über Zeitstempel verfügen, genutzt werden und bietet eine willkommene Erweiterung.
Im Bereich der Administration gibt es ebenfalls passende Neuerungen für den Objektspeicher. Unter der Registerkarte Objektspeicher lassen sich neue Überwachungsfunktionen finden, die den Speicherverbrauch in Datei-Spaces und die Verwendung der Apache-Spark-Anwendungen betreffen. So kann nachvollzogen werden, wo in den Datei-Spaces (oder SAP-HANA-Data-Lake-Dateien) der Verbrauch am höchsten ist und wie die Apache-Spark-Anwendungen arbeiten.
Als zusätzliche neue Option im Objektspeicher gibt es unter „Anforderungen“ nun die Möglichkeit, die erwartete Anzahl an API-Aufrufen im Monat zu definieren. Auf diese Weise können die API-Anforderungen separat definiert werden, wodurch mehr Kontrolle und Genauigkeit bei der Einschätzung des Objektspeicherbedarfs vorhanden ist. Zusammen mit den neuen Überwachungsfunktionen kann der Objektspeicher genauer analysiert werden, um eine präzise Konfiguration hinsichtlich des Speicherbedarfs und der Kosten umzusetzen.
Daneben gibt es weitere Updates zur Verwaltung des SAP Datapshere-Tenants. Administratoren müssen keine Tickets mehr aufgeben, um SAP HANA für SQL Data Warehousing zu aktivieren. Die Zuordnung zwischen SAP Datasphere-Tenant und SAP-Business-Technology-Platform-Konto kann selbst vorgenommen werden. Der Prozess der Einrichtung kann flexibler und schneller vorgenommen werden. Dabei reduziert die SAP Wartezeiten und gibt Administratoren mehr Kontrolle über Ihre Systeme.
Für die SAP Dataphere-Tenants ist zudem die Option der „SAP HANA Multi-Availability Zones aktivieren“. Dadurch kann auf der Seite „Tenant-Konfiguration“ ein synchrones Replikat des Hauptsystems in einer anderen Region erstellt werden. Das synchrone Replikat hat ein Hochverfügbarkeits-Setup, dass bei Bedarf die Verarbeitung übernehmen kann. Die verschiedenen Regionen stellen sicher, dass auch bei Problemen in einzelnen Zonen, die Arbeitslast aufgeteilt werden kann und alle Services zur Verfügung stehen.
Als letzte Neuerung im Bereich der Administration möchte ich Ihnen gerne, die meiner Meinung nach wichtigste Erweiterung, vorstellen. Es kann ein OAuth-Client mit dem Zweck „Technischer Nutzer“ angelegt werden. Dieser ermöglicht eine Nutzung der SCIM-2.0-API für die Benutzer und Rollenverwaltung, den Transport von Inhalten über SAP Cloud Transport Management, den Export von Nutzeraktivitäten als CSV und die Verwendung der datasphere-Befehlszeilenschnittstelle aktuell im Bereich der „marketplace“ Funktionen.
Der „Technische Nutzer“ ermöglicht eine interaktionslose Automatisierung von wiederauftretenden Prozessen und benötigt dafür keine grafische Oberfläche wie einen Browser. Interaktion mit Services, wie beispielsweise im SAP BTP Cockpit, kann so ohne manuelle Eingaben ablaufen. Man kann hoffen, dass die SAP die Funktionalitäten des technischen Nutzers in den kommenden Updates erweitert, um eine stetig bessere Verwaltung des Systems zu ermöglichen.
Falls Sie ein SAP BW/4HANA-Systemen nutzen, kann dies nun direkt mit dem Katalog verbunden werden. Danach können verschiedene Objekte in den Katalog aufgenommen werden, wie AREA (InfoArea), ELEM (BW-Query), IOBJ (InfoObject) und weitere. Ein Katalogadministrator kann die Objekte mit Begriffs-, KPI- und Tag-Bezeichnungen anreichern, um sie für eine einfachere Suche zu veröffentlichen. Die direkte Anbindung macht eine Integration und Verarbeitung der Objekte über andere Wege überflüssig und ermöglicht eine nahtlose Anbindung über BW/4HANA-Syteme, um seinen Katalog effizient zu pflegen. Für konkrete Einschränkungen der Systeme und den zu extrahierenden Objekten, kann auf die SAP-Dokumentation zurückgegriffen werden: SAP-Dokumentation.
Für die ELEM-Objekte in Ihren SAP Analytics Cloud-Story, für Datenprodukte mit SAP Datasphere als Quelle und die SAP Analytics Cloud-Insight mit einem lokalem SAP Datasphere-System ist nun ein erweitertes „Analyse der Auswirkungen und Herkunft-Diagramm“ verfügbar. Dadurch lassen sich Abhängigkeiten direkt erkennen und notwendige Änderungen gezielt durchführen oder fehlende Objekte einfügen.
Im Zuge der Optimierungen und neuen Funktionen im Datenkatalog, wird auch die Benutzerfreundlichkeit der Katalogumgebung insgesamt verbessert. Darunter befinden sich aktualisierte Avatare und Farben für die Rasteransicht auf der Katalogsuchseite, angepasste Seiten zum Anlegen und Verwalten von den erwähnten Glossarbegriffen und KPIs oder auch Verbesserungen der Metadatenextraktionen. Die SAP zeigt, dass sie nicht nur die Funktionalitäten des Datenkatalogs erweitern, sondern auch die Nutzererfahrung verbessert wird. Der Einstieg, sowie die Nutzung, werden so erleichtert und der Datenkatalog attraktiver gestaltet.
Die SAP bietet mit den neusten Änderungen eine Vielzahl von Werkzeugen der Automatisierung, über Aufgabenketten, Replikationsflüssen und dem „Technischen Nutzer“ und macht manuelle Eingreifen seltener notwendig. Die gewonnene Zeit lässt sich für eine ebenfalls optimierte Analyse der eigenen Modelle und Datenprodukte nutzen. Die SAP verbessert so kontinuierlich die Handhabung der SAP Datasphere und steigern gleichzeitig den Mehrwert, den Sie aus ihren Daten bekommen.
Der SAP Road Map Explorer gibt einen Überblick auf die kommenden Entwicklungen. Hier werden quartalsweise die geplanten Updates und Ideen präsentiert, die die Qualität der SAP Datasphere weiterhin gestalten und prägen.
Nichts verpassen.
Blogartikel abonnieren.
