Highlight

Successful together – our valantic Team.
Meet the people who bring passion and accountability to driving success at valantic.
Get to know usIt has been a few weeks since we last updated you on the latest innovations in SAP Datasphere. Consequently, the time has come to take another look at the most exciting changes. We will focus on what we believe are the most important and exciting innovations implemented in the Data Fabric, including the topics of data integration, data modeling, and data cataloging.
Data integration
The most exciting change for SAP Datasphere modelers is likely the introduction of transformation flows. These allow data to be loaded from one or more source tables, transformations such as joins to be applied, and the result to be output to a target table.
In contrast to the existing data flows, it is only possible to integrate data from existing tables in SAP Datasphere. The result is also written back to SAP Datasphere as a local table.
Another new feature is the partitioning of tables in SAP Datasphere. This lets modelers better manage tables containing large data volumes and distribute these over lower-volume tables. At the same time, users can now enable a new option when defining the partition to assess the columns’ suitability for partitioning. This involves sorting the columns to determine the probably most suitable one and outputting information on the factors that influence the partitioning.
As usual, the existing connection types have been improved and further extended. For example, it is now possible to use data flows for a “Google BigQuery” connection for data integration and to specify a region when creating the connection.
Data modeling
A particularly large number of new features have been implemented for data modeling. When creating SQL views, it is now possible to make use of the SAP S/4HANA Cloud window functions. This allows analytical operations such as RANK and WEIGHTED_AVG to be performed.
It is commonly known that local tables are used as the source or target objects of many Datasphere objects. These are now able to capture, or track, changes (deltas). This is done by enabling the Delta Capture option. When this is done, a new table is created in which two additional columns are automatically added next to the key of the main table:
SAP BW/4HANA users will already be familiar with the capture feature which has now also made its way into SAP Datasphere. However, two prerequisites must be met before the function can be enabled for a local table: Firstly, the table must not already have been implemented in other Datasphere objects; and secondly, it must define at least one key column.
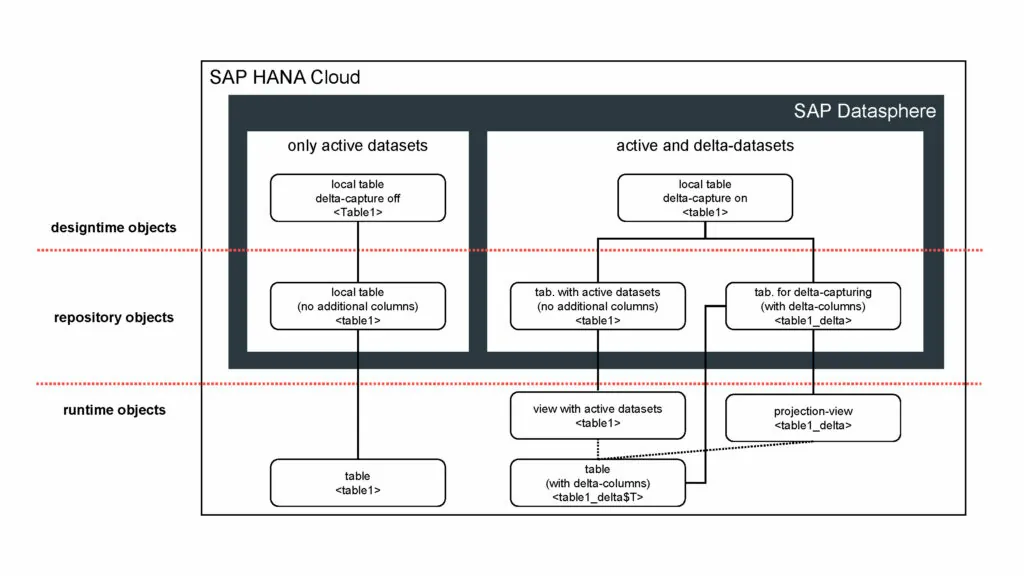
The SAP Datasphere objects use the two mechanisms – Active Records Only and Active & Delta Records – differently. SAP provides detailed information on this in its documentation.
In the course of these innovations, package modeling – which is already known from the Transport functionality of SAP multi-system landscapes – has also found its way into Datasphere. Users with the DW Space Administrator role can create packages to form groups of objects that can be transported between tenants after the modeling process is finished. In doing so, updated versions of the same package can also be transported repeatedly.
Data cataloging
Besides a range of ergonomic improvements and changes to the GUI, a new “Details” tab has been added to the Data Catalog for Assets. This tab contains detailed metadata for the corresponding asset, which includes specific columns, attributes, metrics, dimensions, and properties for each data object. Before the information relating to already imported assets can be displayed, however, they must first be resynchronized.
In addition, it is now possible to connect multiple SAP Datasphere tenants to the catalog. This feature is especially interesting for companies wishing to centralize their data cataloging and use multiple tenants, as well as for system landscapes with development/test and production tenants.
Other new features
Besides the wide range of new features introduced above, there are several other updates we would like to mention.
The change to IP allowlists, which now enables the annotation of IPs, is particularly user-friendly because system or server names, for example, can now be stored to identify the IPs.
Another noteworthy change has been implemented for website titles and linking between Datasphere objects. In earlier versions, the website title never changed, even if different objects were open in different tabs. This has now been improved to allow easy navigation in the browser.
Lastly, contexts of the type “Internal Data Marketplace” can now also be created to allow internal data sharing with users of the same or a specified tenant. This simplifies the distribution of data products within an organization and enhances Data stewardship.
Outlook
For future updates, we recommend referring to SAP’s Roadmap Explorer to ensure you always know about revised schedules and new features in SAP Datasphere.
With the innovations that SAP has already published for SAP Datasphere 2023, we believe that SAP is taking the right step towards a Data Fabric. The brimming roadmap points towards a very exciting future.
We look forward to giving you a detailed introduction to SAP Datasphere. Please get in touch!

Artificial Intelligence July 15, 2026
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
SAP Sapphire has refined the vision of the Autonomous Enterprise—now it’s time to put it into practice. Part 2 of our blog series highlights four key building blocks: transparent architecture and agent governance with LeanIX, the path to the cloud, a solid data foundation in the SAP Business Data Cloud, and processes made visible through process mining.
Homework for the Autonomous Enterprise: Architecture, Data, and Processes
Work@valantic June 10, 2026
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Florian Steinwendtner is Head of SAP Cloud Advisory and leads the logistics team at valantic in Austria. In this interview, he talks about his extraordinary path from landscape gardener to SAP consultant, his enthusiasm for SAP Cloud ERP, and how he is helping to drive valantic's SAP Cloud Powerhouse forward.
Florian’s SAP career: How he is advancing the cloud business at valantic in Austria
Artificial Intelligence June 9, 2026
SAP Sapphire 2026 – the way into the Autonomous Enterprise
SAP Sapphire 2026 marks the mindshift from assistant to agent: In the Autonomous Enterprise, Joule Assistants orchestrate networked agents that perform routine work independently across SAP and non-SAP systems. They are based on Joule Work and Joule Studio, the SAP Business Data Cloud and the Business AI Platform - provided that the data, cloud setup and culture are in sync.
SAP Sapphire 2026 – the way into the Autonomous EnterpriseDon't miss a thing.
Subscribe to our latest blog articles.

