…
zeigt Kompetenzen auf, die zur erfolgreichen Durchführung eines Projektes
vonnöten sind.
…
stellt alle Interessengruppen eines Data-Science-Projektes in den Fokus.
… übernimmt
die Einfachheit etablierter Vorgehensmodelle für Data-Mining-Projekte,
erweitert sie aber um Besonderheiten des Data-Science-Komplexes.
Motivation
Das Thema Data Science hat in den
letzten Jahren in vielen Organisationen stark an Aufmerksamkeit gewonnen.
Häufig herrscht jedoch weiterhin große Unklarheit darüber, wie diese Disziplin von
anderen abzugrenzen ist, welche Besonderheiten der Ablauf eines
Data-Science-Projekts besitzt und welche Kompetenzen vorhanden sein müssen, um
ein solches Projekt durchzuführen.
In der Hoffnung, einen kleinen Beitrag zur Beseitigung dieser Unklarheiten leisten zu können, wurde von April 2019 bis Februar 2020 in einer offenen und virtuellen Arbeitsgruppe mit Vertretern aus Theorie und Praxis, darunter die valantic-Experten Daniel Badura, Heiko Rohde und Michael Schulz, ein Vorgehensmodell für Data-Science-Projekte erstellt – das Data Science Process Model (DASC-PM). Ziel war es dabei nicht, neue Herangehensweisen zu entwickeln, sondern vielmehr, vorhandenes Wissen zusammenzutragen und in geeigneter Form zu strukturieren. Das Ergebnis ist als Zusammenführung der Erfahrung sämtlicher Teilnehmerinnen und Teilnehmer der Arbeitsgruppe zu verstehen.
Auf Basis der Teilnehmerbeiträge aus
der Arbeitsgruppe wird folgende Definition des Data-Science-Begriffes
empfohlen:
Data Science ist ein interdisziplinäres Fachgebiet, in welchem mit Hilfe eines wissenschaftlichen Vorgehens, semiautomatisch und unter Anwendung bestehender oder zu entwickelnder Analyseverfahren Erkenntnisse aus teils komplexen Daten extrahiert und unter Berücksichtigung gesellschaftlicher Auswirkungen nutzbar gemacht werden.
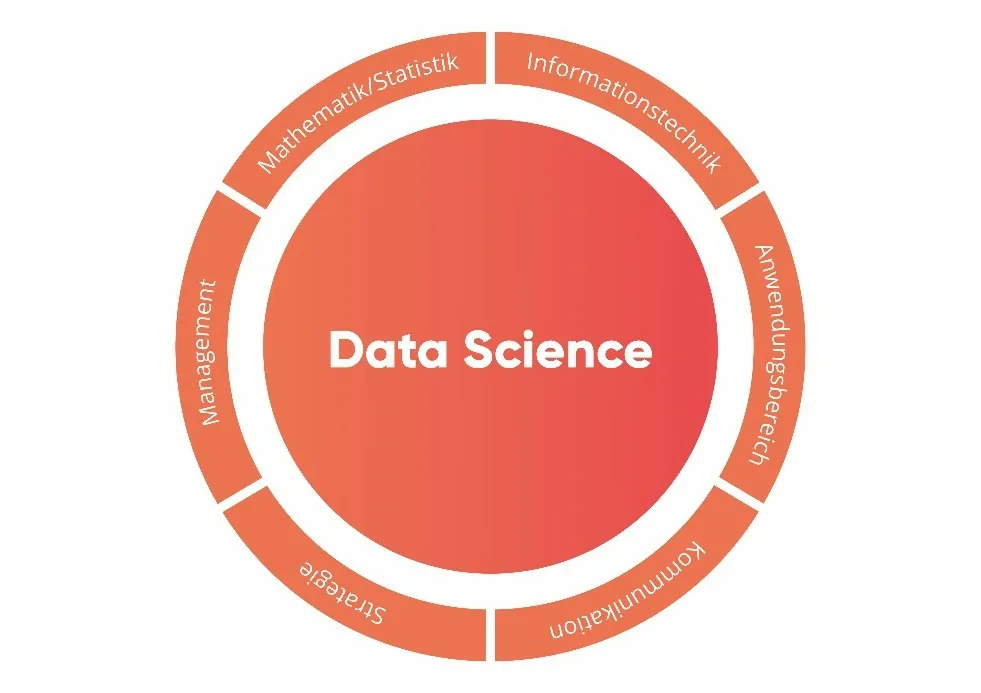
In verschiedenen Quellen werden aufbauend auf einem Beitrag von Conway (2010) von einem Data Scientist Kompetenzen in mathematisch-statistischen, informationstechnischen und anwendungsspezifischen Bereichen gefordert. Weiterhin müssen Data Scientists in der Lage sein, mit allen Anspruchsgruppen in einer geeigneten Sprache zu kommunizieren (Davenport & Patil, 2012), das Management eines Data-Science-Projektes zu übernehmen und die strategische Einordnung von Aktivitäten vorzunehmen. Abbildung 1 fasst sämtliche Kompetenzen zusammen, die für die Durchführung von Data-Science-Projekten benötigt werden. Für eine einzelne Person ist es in der Regel nicht möglich, tiefe Fähigkeiten in allen genannten Bereichen aufzubauen (Zschech et al., 2018). Data Scientists können sich daher entweder in einer Disziplin bzw. wenigen Disziplinen spezialisieren oder übergeordnete bzw. weniger datenorientierte Rollen übernehmen.
Nötige Kompetenzen in einem Data-Science-Projekt
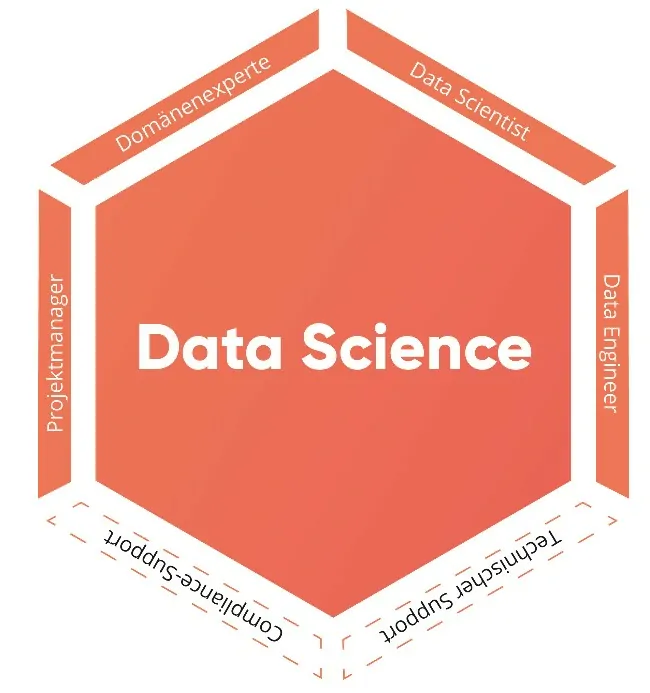
Um der sich etablierenden Spezialisierung innerhalb von Data-Science-Projekten Rechnung zu tragen, werden vermehrt verschiedene Rollen unterschieden. Im Folgenden werden die Rollen dargestellt, die von den Teilnehmerinnen und Teilnehmern der Arbeitsgruppe als relevant identifiziert wurden, um sämtliche notwendigen Aktivitäten eines Data-Science-Projektes abzudecken. Bei großen Projekten werden die hier beschriebenen Rollen häufig noch in spezifischere Unterrollen aufgeteilt. Eine Rolle entspricht nicht zwangsläufig einer Person. Sie kann entweder auf mehrere Personen innerhalb eines Projektes aufgeteilt werden oder es können, gerade bei kleinen Projekten, mehrere Rollen von einer Person übernommen werden. In Abbildung 2 sind die Rollen innerhalb eines Data-Science-Projektes zusammengefasst.
Rollen in einem Data-Science-Projekt
Vorgehensmodell DASC-PM
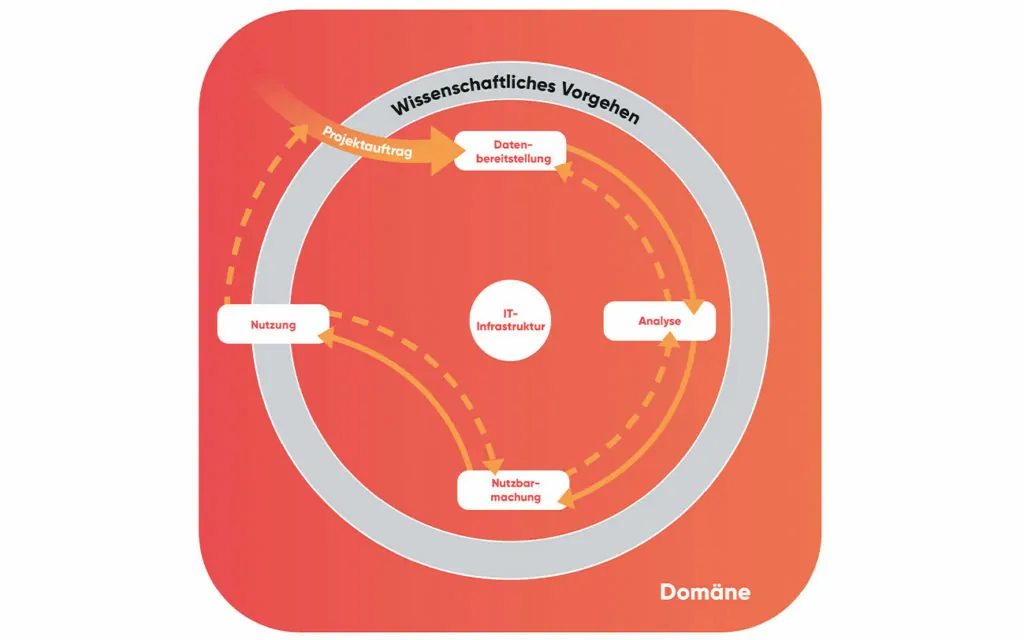
Die Visualisierung des Data Science Process Models (DASC-PM), dargestellt in Abbildung 3, soll das Vorgehen innerhalb eines Projektes vereinfacht und prägnant aufzeigen. Analysevorhaben können von sehr unterschiedlicher Größe, Komplexität und Schwerpunktsetzung sein. Nicht alle adressierten Aufgaben sind im individuellen Projekt daher in gleichem Maße zu berücksichtigen. Unabhängig von der Ausgestaltung im konkreten Anwendungsfall sollte jedoch bei allen im Folgenden dargestellten Phasen geklärt werden, ob die jeweils enthaltenen Aufgaben berücksichtigt werden müssen.
Abbildung 3: Das Data-Science-Process-Model – kurz: DASC-PM – beschreibt das Vorgehen in einem Data-Science-Projekt.
Die im Modell dargestellten,
durchgezogenen Pfeile bilden den primären Pfad bei der Verwendung des DASC-PM.
Die gestrichelten Pfeile zeigen die Möglichkeit von Rückkopplungen zu
vorherigen Phasen, die durch die Gewinnung neuer Erkenntnisse im Projektverlauf
immer wieder nötig sein können.
Eingebettet ist ein Analysevorhaben in
die Domäne. Innerhalb dieser werden Anwendungsfälle identifiziert, die
eine datenwissenschaftliche Betrachtung rechtfertigen. Aus einem oder mehreren
Anwendungsfällen wird ein Projektauftrag formuliert, der in Form eines Data-Science-Projektes
zu bearbeiten ist. Können in dieser Phase aus der Domäne heraus explizite
Aufgaben formuliert werden, stellen diese in anderen Phasen häufig
domänenspezifische Rahmenbedingungen dar, die Aufgaben beeinflussen. Die Domäne
muss daher durchgängig berücksichtigt werden.
Der definierte Projektauftrag ist in
jeder einzelnen Projektphase dem wissenschaftlichen Vorgehen entsprechend
zu bearbeiten. Hervorzuheben sind hier vor allem das Projektmanagement und eine
strukturierte Bearbeitung, die bereits durch die Verwendung eines
Vorgehensmodells in den Vordergrund gestellt wird. Details zum nötigen Grad an
Wissenschaftlichkeit sind unter Berücksichtigung der Projektgegebenheiten und
der Domänenspezifika festzulegen.
Sämtliche Aktivitäten, die dem
Schlüsselbereich Daten zuzuordnen sind, werden innerhalb der Visualisierung des
DASC-PM in der Phase der Datenbereitstellung zusammengefasst, weshalb
der verwendete Begriff hier weit zu fassen ist. Er enthält sowohl, die
Datenaufbereitung (bestehend aus Datenbeschaffung, -integration,
-transformation und ‑speicherung) und das Datenmanagement als auch die explorative
Analyse zur Erkundung der Daten. Als Ergebnis der Bearbeitung dieser Phase entsteht
eine Datenquelle, die aus methodischer und fachlicher Sicht für die Analyse
geeignet ist.
Die Phase der Analyse beinhaltet
alle Aufgaben, die dem Schlüsselbereich Analyseverfahren zuzuordnen sind.
Entweder können in einem Data-Science-Projekt bestehende Verfahren angewendet
oder es müssen zunächst neue Verfahren entwickelt werden. Die Identifikation
geeigneter bestehender Verfahren kann dabei eine große Herausforderung
darstellen. Artefakt dieser Phase ist ein Analyseergebnis, das eine methodische
und fachliche Evaluation durchlaufen hat.
In der Phase der Nutzbarmachung müssen
die Analyseergebnisse so aufbereitet werden, dass sie für die geplante Nutzung
geeignet sind. Die Ergebnisse können abhängig von dem spezifischen Projekt sehr
unterschiedlich sein: Analyseartefakte können aus Ergebnissen bestehen, die den
Adressaten verbal oder in Form von Berichten zur Verfügung gestellt werden.
Weiterhin können Modelle oder auch Analyseverfahren selbst das Ergebnis eines
Data-Science-Projektes sein.
Die sich an die Projektdurchführung
anschließende Nutzung von Analyseartefakten ist nicht als primärer Teil
eines Data-Science-Projektes zu sehen. Ein Monitoring der Verwendung ist aber
abhängig von der konkreten Form der Nutzbarmachung nötig, um die fortbestehende
Eignung des Modells in der Anwendung zu prüfen und ggf. Erkenntnisse aus der
Nutzung für die Weiter- und Neuentwicklung von Analyseartefakten zu
erlangen.
Sämtliche Schritte, die ein
Data-Science-Projekt durchlaufen muss, sind von der zu Grunde liegenden IT-Infrastruktur
abhängig, das tatsächliche Ausmaß ist allerdings projektindividuell zu
bewerten. Auch wenn die Nutzung spezifischer Hard- und Software häufig bereits
organisationsintern festgelegt ist, sollte man, wenn auch nicht die Auswahl, so
doch zumindest die limitierenden und befähigenden Merkmale der IT-Infrastruktur
in sämtlichen Projektphasen berücksichtigen.
Obwohl aus Gründen der Übersichtlichkeit
auf eine Visualisierung dieser Tatsache in Abbildung 3 verzichtet wurde, ist der Abbruch des
Data-Science-Projekts in jeder einzelnen Projektphase als Option zu
berücksichtigen. Auch wenn dadurch das im Projektauftrag definierte Ziel i. d. R.
nicht erreicht werden kann, bedeutet dies nicht zwangsläufig, dass das Projekt
vollständig fehlgeschlagen ist. Erkenntnisse, die bis zum Zeitpunkt des
Abbruchs gesammelt wurden, können innerhalb des bearbeiteten Anwendungsfalls
bzw. der bearbeiteten Anwendungsfälle Verwendung finden.
Das Vorgehensmodell ist – wie alle
Modelle – eine vereinfachte Version der Wirklichkeit. Weder muss es sklavisch
befolgt werden, noch erhebt es den Anspruch, jede Variante und Eventualität
eines Vorgehens oder einer Methodik darzulegen. Es bietet auch keine Anleitung
zur vollständigen Abarbeitung jedes einzelnen abgebildeten Bausteins. Vielmehr
ist das Modell eine solide Grundlage zur Durchführung von Data-Initiativen, da
es auf mehr als nur die Erfahrungen eines einzelnen Unternehmens oder einer einzelnen
Forschungsgruppe zurückgreifen kann. DASC-PM ist daher mehr als ein Best-Practice-Ansatz.
Es ist eine strukturierte, fundierte und umsetzbare Aufbereitung eines der
relevantesten Themen der Wirtschaft und Wissenschaft, namentlich der planvollen
und ergebnisorientierten Nutzbarmachung von Daten, der Data Science.
„Bei der Umsetzung von Data Science Projekten ist ein wissenschaftliches Vorgehen einzuhalten und die IT-Infrastruktur ist in jedem Schritt entsprechend zu berücksichtigen.“
Prof. Dr. Michael Schulz und Uwe Neuhaus von der NORDAKADEMIE haben gemeinsam mit einer virtuellen Arbeitsgruppe ein Data Science Process Modell erstellt.
Foto Quelle: NORDAKADEMIE/Foto: Dirk Schönfeldt
Literatur
Conway, D. (2010). The data science venn diagram.
Dataists, drewconway.com/zia/2013/3/26/the-data-science-venn-diagram.
Davenport, T. H., & Patil, D. J. (2012). Data
scientist. Harvard business review, 90(5), 70-76.
Zschech, P., Fleißner, V., Baumgärtel, N., &
Hilbert, A. (2018). Data Science Skills and Enabling Enterprise
Systems. HMD Praxis der Wirtschaftsinformatik, 55(1),
163-181.
Dieser Beitrag enthält Texte, die
größtenteils gekürzt aus folgender Arbeit entnommen wurden:
Schulz, M., Neuhaus, U., Kaufmann, J., Badura, D., Kerzel, U., Welter, F., Prothmann, M., Kühnel, S., Passlick, J., Rissler, R., Badewitz, W., Dann, D., Gröschel, A., Kloker, S., Alekozai, E. M., Felderer, M., Lanquillon, C., Brauner, D., Gölzer, P., Binder, H., Rohde, H., Gehrke, N. (2020): DASC-PM v1.0 – Ein Vorgehensmodell für Data-Science-Projekte